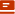 火星网校
火星网校
AI 历史坐标:10 个具有里程碑意义的关键时刻
 作者:奋努的小枫
发布时间: 2026-02-20 08:32:00
浏览量:750次
作者:奋努的小枫
发布时间: 2026-02-20 08:32:00
浏览量:750次
说明:文中所有的配图均来源于网络
2025年,人工智能已从前沿科技圈的热门概念,深度融入我们的日常生活。无论是生成图像、编写代码、实现自动驾驶,还是助力医疗诊断,几乎每个行业都在热烈探讨并积极应用AI。
然而,当下大模型引发的技术奇点并非一蹴而就,其背后是一条充满波折的进化之路,有突破时的振奋、争议中的迷茫、冷寂期的落寞,也有复兴后的辉煌。自1956年达特茅斯会议为人工智能奠基,到如今数千亿参数模型掀起全球技术竞赛热潮,AI的发展历程,实则是人类不断探索如何模拟、拓展乃至重新定义智能的壮丽史诗。
接下来,将带你一同回顾这条发展之路上的10个关键历史时刻,了解人工智能如何从最初的纸上设想,逐步成为当下技术浪潮的核心力量。
1956年,达特茅斯会议如同一束强光,照亮了人工智能(AI)发展的漫漫长路,被公认为人工智能诞生的标志性里程碑。此次会议由约翰·麦卡锡、马文·明斯基、内森·罗切斯特和克劳德·香农这四位人工智能领域的先驱人物共同发起,他们广发“英雄帖”,召集了一群怀揣着对机器智能无限憧憬的研究者。这些志同道合之人齐聚一堂,目标只有一个——探索机器智能这一充满未知的神秘领域。
在长达六周的会议期间,与会者们展开了深度且热烈的讨论、激烈的辩论以及高效的合作。他们尝试为人工智能这一全新概念下定义,明确其研究目标,精心规划可能的研究方向。会议上,成员们围绕问题求解、机器学习、符号推理等一系列深刻问题进行了深入探讨。
这次意义非凡的会议,不仅为之后数十年人工智能的研究与创新拉开了大幕,还凝聚起一个信念坚定的学术群体,他们坚信机器有能力复制人类的认知能力。达特茅斯会议的深远影响不可估量,它正式确立了人工智能作为一门学科和实践领域的地位,引领人类大步迈向智能机器与人类携手共进的美好未来。

1957年,弗兰克·罗森布拉特成功开发出感知机(Perceptron),它作为最早的人工神经网络之一闪耀登场。感知机仿照生物神经元构建,是一个高度简化的模型,主要功能是进行二值分类决策,就像一个精准的“分类小能手”。
虽然感知机模型结构并不复杂,但它首次提出了“用训练数据优化模型”这一具有开创性的思想。这种“训练 - 预测”范式,如同机器学习和深度学习的“基石密码”,后来成为其核心方法。它为如今广为人知的神经网络和深度学习技术奠定了坚实基础。
尽管感知机存在不能处理非线性可分问题等局限,却如同一把钥匙,打开了后续更复杂模型研究的大门。时至今日,感知机的影响力依旧强劲,在图像识别、语音处理、自然语言理解等前沿领域发挥着作用。
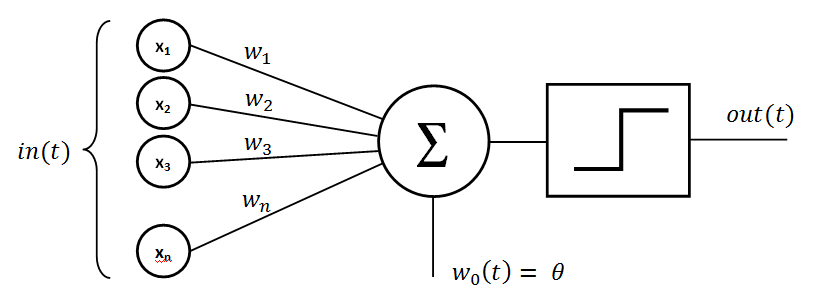
1966年,MIT计算机科学家约瑟夫·维森鲍姆(Joseph Weizenbaum)成功打造出ELIZA,它作为首个被广泛认可的聊天机器人,在人工智能发展历程中留下了浓墨重彩的一笔。ELIZA巧妙地以心理治疗为模拟场景,运用独特的“罗杰式对话法”,把用户的回答转化为追问,让对话得以自然延续,仿佛一位耐心倾听的心理医生。
维森鲍姆开发ELIZA的初衷,本是想借此揭示机器智能的“拙劣”之处。然而,现实却与他开了个玩笑,许多用户深陷对话之中,竟真的以为自己在和真正的心理医生交流。他在论文中感慨:“有些被试很难相信ELIZA不是人类。”
尽管以如今的眼光审视,ELIZA的功能显得十分基础,但它却如同一颗火种,首次展示了人工智能在自然语言处理领域的巨大潜力。它通过与用户的对话,证明计算机能够生成类似人类的回应,成功点燃了人们对对话式AI领域的探索热情。
20世纪70年代,AI研究聚焦于符号主义,以逻辑推理为核心展开探索。彼时,专家系统如璀璨新星般兴起,Dendral和MYCIN便是其中的典型代表,它们标志着人工智能首次在实际领域中初显类人智能的锋芒。
Dendral专为化学领域打造,它如同一位经验丰富的化学专家,能够精准分析质谱数据,进而推断出有机化合物的分子结构,充分展现了AI在专业领域模拟专家推理的卓越能力。而MYCIN则将目光投向医疗诊断领域,它能够准确识别细菌感染类型,并为其量身定制抗生素治疗方案。
这些专家系统有力地证明,AI不仅能应对通用逻辑问题,还能化身特定领域的“知识专家”,为AI在医疗、法律、金融、工程等专业领域的广泛应用奠定了基础。

1997年IBM超级计算机深蓝与世界象棋冠军加里·卡斯帕罗夫展开的那场历史性象棋对局,如同一场科技与智慧的巅峰对决,吸引了全球目光。深蓝最终取得胜利,这一壮举成为人工智能发展进程中的重要里程碑,证明了机器能在复杂游戏中,凭借战略思维、评估决策超越人类。

计算机科学家汤姆·米切尔(Tom Mitchell)给出的机器学习定义别具深意,他将机器学习界定为“对计算机算法的研究,该研究旨在让程序能借助经验积累,自动提升自身性能”。这一定义宛如一座里程碑,标志着人工智能研究方向的重大转变,凸显数据驱动算法的关键意义,推动着AI系统不断适应与进化。

深度学习(Deep Learning)作为机器学习领域的重要算法分支,其核心在于借助多层神经网络结构,搭配“反向传播”(Backpropagation)技术开展模型训练。这一领域的根基,是由被誉为“深度学习之父”的Geoffrey Hinton奠定的。
时光回溯到1986年,Hinton与合作者发表了关于深度神经网络(DNN,Deep Neural Networks)的开创性论文,首次系统性地引入了反向传播算法。这一算法犹如一把“金钥匙”,在训练过程中能够动态地调整网络中的权重参数,让神经网络可以更精准、高效地逼近正确输出,成功实现了对多层网络的高效训练。它打破了Minsky在1966年提出的感知器局限,成为神经网络发展历程中的关键转折点,引领神经网络研究迈向新的高度。
此后,深度学习不断发展。AlexNet在ImageNet竞赛中一鸣惊人,取得了震撼业界的成绩,如同投入平静湖面的巨石,瞬间引爆了深度学习的发展浪潮,推动其进入快速发展阶段。
伊恩·古德费洛(Ian Goodfellow)宛如一位开拓者,提出了生成对抗网络(GANs)这一具有划时代意义的概念,彻底革新了生成模型领域。GANs构建起一个独特的框架,由生成器和判别器这两个神经网络相互博弈、彼此竞争。凭借这一框架,创建逼真的合成数据,如图像、文本等成为现实,还在图像合成、视频生成、数据增强等多个应用领域激起了深远而持久的涟漪。

DeepMind精心打造的AlphaGo,完成了堪称非凡的壮举——它成功击败世界围棋冠军李世石。围棋棋局变幻无穷,每一步都蕴含着海量可能,极度考验直觉与战略思维。AlphaGo在此复杂游戏中获胜,这一里程碑意义非凡,它如同一束强光,清晰照亮了人工智能在攻克人类专属挑战方面的巨大潜力。

大语言模型的蓬勃发展,始于2017年Transformer架构的横空出世。这一架构所搭载的自注意力机制,宛如一把精准的手术刀,有效解决了长距离依赖这一棘手难题,为大语言模型理解和生成长文本筑牢了根基。
2018年,大语言模型领域迎来关键转折。GPT - 1与BERT分别基于自回归和遮蔽语言模型的预训练方式,确立了“预训练 + 微调”的经典范式。这一范式让模型如同海绵吸水一般,能从海量无标注语料中汲取通用语言能力,实现知识的快速积累。
2020年,GPT - 3凭借高达1750亿的参数规模,初步展现出令人惊叹的“涌现能力”。它不仅能进行零样本学习,还能完成逻辑推理与代码生成等复杂任务,标志着模型规模扩大带来的质变,为大语言模型发展开辟了新路径。
2023年,大语言模型发展再上新台阶。GPT - 4融合文本与图像的多模态能力,并通过人类反馈强化学习(RLHF)大幅提升模型的安全性与实用性。与此同时,Anthropic推出Claude,Google发布Gemini系列,Meta发布开源模型LLaMA。国内大模型生态也欣欣向荣,百度的文心一言、阿里的通义千问、字节的豆包等纷纷涌现,DeepSeek更是凭借开放参数和高性价比模型掀起大众AI热潮,成为行业焦点。
从1956年达特茅斯会议上那充满憧憬的一纸设想,到2025年大模型在千行百业落地生根,人工智能的发展绝非坦途,而是一条蜿蜒曲折、充满惊喜的演化长卷。这10个关键节点,宛如人类探索智能本质、突破技术边界征程中的璀璨路标,见证着一次次重要的集体跃迁。回溯过往,不仅是对里程碑的深情致敬,更是为了洞悉当下现象的根源。或许,下一次具有突破性意义的转折点正悄然临近。







相关文章



")
















最新发布










推荐教程
-
 视频剪辑培训十大常见误区,资深剪辑师避坑指南
视频剪辑培训十大常见误区,资深剪辑师避坑指南 -
 最新就业趋势下建模培训必备的7项专业技能
最新就业趋势下建模培训必备的7项专业技能 -
 最新十大游戏开发培训机构实战课程对比评测
最新十大游戏开发培训机构实战课程对比评测 -
 优质动漫绘画培训机构筛选标准全攻略
优质动漫绘画培训机构筛选标准全攻略 -
 免费影视制作资源库:专业软件与插件合集推荐
免费影视制作资源库:专业软件与插件合集推荐 -
 零基础影视剪辑教程:30天掌握核心剪辑思维
零基础影视剪辑教程:30天掌握核心剪辑思维 -
 剪辑师培训全流程:从基础剪辑到高级特效指南
剪辑师培训全流程:从基础剪辑到高级特效指南 -
 短视频与长视频剪辑师培训需求差异深度解析
短视频与长视频剪辑师培训需求差异深度解析 -
 跨平台短视频培训:抖音B站小红书运营差异
跨平台短视频培训:抖音B站小红书运营差异 -
 视频剪辑避坑指南:识别优质课程的七个维度
视频剪辑避坑指南:识别优质课程的七个维度 -
 AI技术融合:3d建模培训班最新行业趋势解析
AI技术融合:3d建模培训班最新行业趋势解析 -
 Maya与Blender动漫制作软件对比全攻略
Maya与Blender动漫制作软件对比全攻略 -
 免费手绘学习资源库:线稿素材与笔刷合集推荐
免费手绘学习资源库:线稿素材与笔刷合集推荐 -
 插画培训价格解析:不同课程性价比深度对比
插画培训价格解析:不同课程性价比深度对比 -
 好莱坞认证课程:国际影视制作标准实战解析
好莱坞认证课程:国际影视制作标准实战解析 -
 如何选择游戏开发引擎?Unity与Unreal对比测评
如何选择游戏开发引擎?Unity与Unreal对比测评
猜你喜欢











优秀作品赏析

作 者:李思庭
所学课程:2101期学员李思庭作品

作 者:林雪茹
所学课程:2104期学员林雪茹作品

作 者:赵凌
所学课程:2107期学员赵凌作品

作 者:赵燃
所学课程:2107期学员赵燃作品
