 火星网校
火星网校
二、 AI数字绘画—Stable Diffusion简介
发布时间:2024-03-24 18:27:06 浏览量:193次
Stable Diffusion是目前最火的AI绘画工具之一,它是一个免费开源的项目,可以被任何人免费部署和使用。通过Stable Diffusion,可以很轻松的通过文字描述,生成对应的图片。
Stable Diffusion是一个深度学习文本到图像生成模型,是stability.ai开源的图像生成模型,而Stable Diffusion WebUI把Stable Diffusion模型进行了封装,提供更加简洁易操作的界面。他们两个的关系类似父子继承关系,目前使用的最多的是Stable Diffusion WebUI,因为它界面友好,可以很方便的调整各项参数,生成高质量的图片。
使用Stable Diffusion之前,有几个重要的组件,需要首先了解:
1 模型,模型可以简单理解,你想画什么风格的画。模型包括大模型(基础模型)、Lora(微调模型)、VAE模型(变分自编码器)、Embeding(提示词打包)、Hypernetworks 用的比较少。
大模型,是SD能够绘图的基础模型。安装完SD软件后,必须搭配基础模型才能使用。不同的基础模型,其画风和擅长的领域会有侧重。
Lora模型,是与大模型配套使用,用于抽取画作的风格特征(例如人物特征属性),创作出相似度非常高的作品。
VAE模型,全名Variational autoenconder,中文叫变分自编码器,与大模型配套使用,VAE模型具有两种功能,一种是滤镜(就像是PS、抖音、美图秀秀等)用到的滤镜一样,让出图的画面看上去不会灰蒙蒙的,让整体的色彩饱和度更高。另一种是微调,部分VAE会对出图的细节进行细微的调整(个人觉得变化并不明显仅会对细节处微调)
Embeding、Hypernetworks用的比较少,暂不介绍。
2 插件,插件就是扩展,插件就是给Stable Diffusion这套系统附魔的。就是说,通过插件,我们的Stable Diffusion就会有更多的功能,我们耳熟能详的ControlNet其实就是Stable Diffusion里的一个插件。
常用插件:sd-webui-mov2mov(AI视频转换)、ControNet(提取人物自身、提取图像纹理结构)、zh_CN汉化、tag_complete标签自动补齐、cutoff、bilingual_localization双语提示、Segment anything(它可以快速地把你想要切割的部分分割出来)
3 提示词,Prompt,有些地方也称之为关键词,主要目的是我们通过提示词,告诉Stable Diffusion我们需要什么样的图。
而提示词则分为正向提示词和反向提示词,正向提示词是告诉Stable Diffusion我们要什么,比如best quality,4k,1girl,这就是告诉Stable Diffusion我们要画的内容里要包括最好画质,4K分辨率,1个女孩。
而反向提示词则可以是Twisted fingers, multiple heads, multiple arms,当你把这个放进反向提示词里,则是告诉Stable Diffusion
输入框如下:
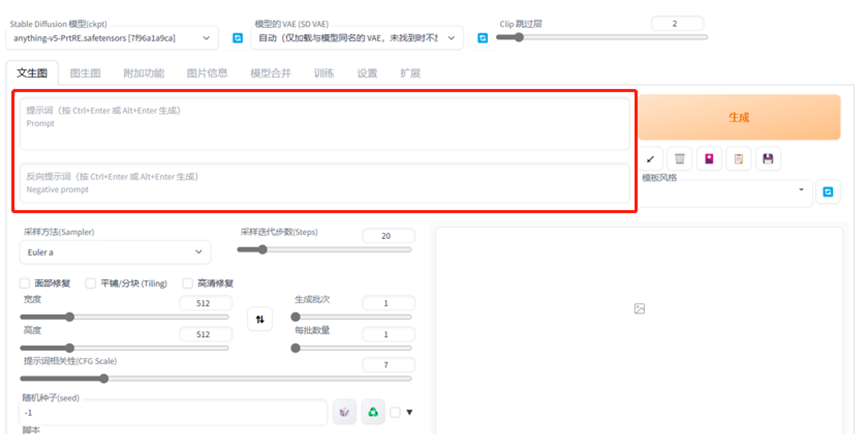
4 常用模型参考:
Model:DreamShaper

Model:majicMIX realistic

Model:MeinaMix

Model:SarkSun





热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
