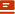 火星网校
火星网校
爆火!最强Text-to-3D开源方案LucidDreamer:毛发都给你合成出来
发布时间:2024-03-24 19:39:10 浏览量:193次
作者:泡椒味的口香糖 | 来源:3D视觉工坊
在公众号「3D视觉工坊」后台,回复「原论文」可获取论文pdf、代码链接
添加微信:dddvisiona,备注:NeRF,拉你入群。文末附行业细分群
0. 笔者个人体会
最近单图像合成3D、文本合成3D等等工作可谓大火,不停的看见"10秒/45秒/1分钟内合成高保真3D模型"的标题,大多数都是基于扩散模型和NeRF二次开发的,官方主页展示的交互式demo也确实效果拔群。
但是大多数方案合成的3D模型还是太过于平滑了,对于毛发、皮肤纹理、金属质感这种高频细节处理的不太好,很难说达到了照片级渲染。今天笔者将为大家分享香港科技大学、之江实验室、浙江大学最新开源的工作LucidDreamer,合成的模型非常精细!
下面一起来阅读一下这项工作,文末附论文和代码链接~
1. 效果展示
给定文本提示,LucidDreamer可以合成高保真的3D模型,可以发现合成的模型真的是很精细了,保留了非常多的高频细节。3D建模师又要睡不着觉了~这里也推荐工坊推出的新课程《零基础入门四旋翼建模与控制(MATLAB仿真)[理论+实战]》。


2. 具体原理是什么?
现有Text-to-3D方案在渲染3D模型的高频细节上处理效果不太好,这是因为现有方案大多基于SDS(Score Distillation Sampling)进行,造成了模型的过度平滑。
因此,作者换了一个技术路线:提出一种区间得分匹配(Interval Score Matching,ISM)的新方法。ISM采用确定性的扩散轨迹,并利用基于区间的得分匹配来抵消过度平滑。此外,还将3D高斯splatting(ACM SIGGRAPH 2023会议最佳论文)融入到文本到3D中来提高渲染速度。
具体的框架是,首先通过预训练的text-to-3D生成器初始化3D表示θ(实际操作用的是高斯splatting),结合预训练的2D去噪扩散概率模型,使用DDIM反演将随机视图扰动为无条件噪声的潜在轨迹,最后使用作者提出的ISM来更新θ。
3. 再来看看和同类方法的对比
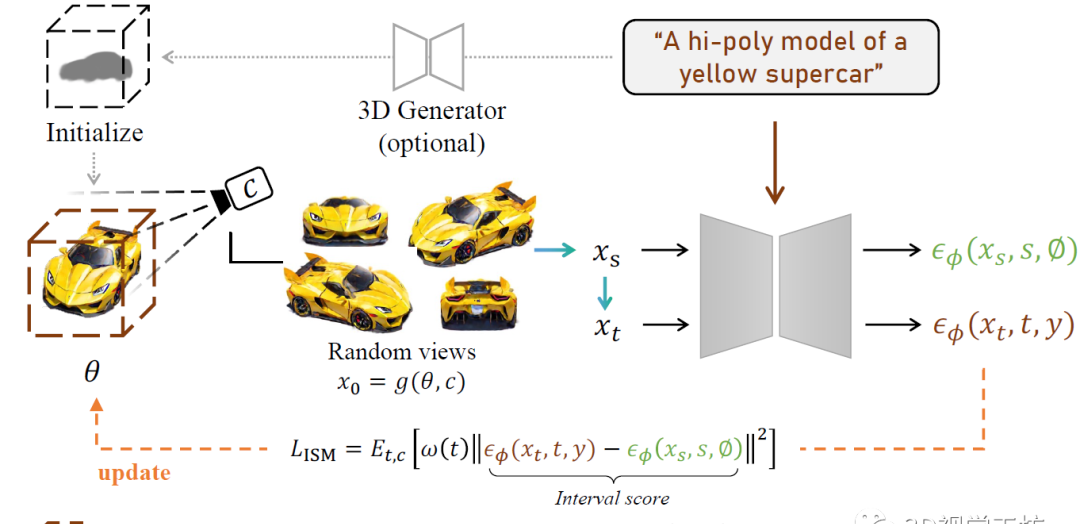
看一下和同类text-to-3D的效果对比,其他方案要么出现了语义歧义,要么渲染速度过慢。

作者提出的ISM和同类SDS策略的对比,可以发现ISM很大程度上预测了3D物体的高频细节,使得模型更贴近照片级渲染!

作者还展示了ISM的应用价值,包括2D/3D编辑、3D虚拟任务生成、个性化3D生成,进一步扩展了这项工作的意义。这里也推荐工坊推出的新课程《零基础入门四旋翼建模与控制(MATLAB仿真)[理论+实战]》。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~




热门课程推荐

热门资讯
-
探讨游戏引擎的文章,介绍了10款游戏引擎及其代表作品,涵盖了RAGE Engine、Naughty Dog Game Engine、The Dead Engine、Cry Engine、Avalanche Engine、Anvil Engine、IW Engine、Frostbite Engine、Creation引擎、Unreal Engine等引擎。借此分析引出了游戏设计领域和数字艺术教育的重要性,欢迎点击咨询报名。
-
2. 手机游戏如何开发(如何制作传奇手游,都需要准备些什么?)
如何制作传奇手游,都需要准备些什么?提到传奇手游相信大家都不陌生,他是许多80、90后的回忆;从起初的端游到现在的手游,说明时代在进步游戏在更新,更趋于方便化移动化。而如果我们想要制作一款传奇手游的
-
3. B站视频剪辑软件「必剪」:免费、炫酷特效,小白必备工具
B站视频剪辑软件「必剪」,完全免费、一键制作炫酷特效,适合新手小白。快来试试!
-
游戏中玩家将面临武侠人生的挣扎抉择,战或降?杀或放?每个抉定都将触发更多爱恨纠葛的精彩奇遇。《天命奇御》具有多线剧情多结局,不限主线发展,高自由...
-
三昧动漫对于著名ARPG游戏《巫师》系列,最近CD Projekt 的高层回应并不会推出《巫师4》。因为《巫师》系列在策划的时候一直定位在“三部曲”的故事框架,所以在游戏的出品上不可能出现《巫师4》
-
6. 3D动画软件你知道几个?3ds Max、Blender、Maya、Houdini大比拼
当提到3D动画软件或动画工具时,指的是数字内容创建工具。它是用于造型、建模以及绘制3D美术动画的软件程序。但是,在3D动画软件中还包含了其他类型的...
-
想让你的3D打印模型更坚固?不妨尝试一下Cura参数设置和设计技巧,让你轻松掌握!
-
众所周知,虚幻引擎5(下面简称UE5)特别占用存储空间,仅一个版本安装好的文件就有60G,这还不包括我们在使用时保存的工程文件和随之产生的缓存文件。而...
-
9. Bigtime加密游戏经济体系揭秘,不同玩家角色的经济活动
Bigtime加密游戏经济模型分析,探讨游戏经济特点,帮助玩家更全面了解这款GameFi产品。
-
10. 3D动漫建模全过程,不是一般人能学的会的,会的多不是人?
步骤01:面部,颈部,身体在一起这次我不准备设计图片,我从雕刻进入。这一次,它将是一种纯粹关注建模而非整体绘画的形式。像往常一样,我从Sphere创建它...
最新文章
