 火星网校
火星网校
计算机行业AIGC:GPT-4v如何实现强大多模态,从文生图到图生文
发布时间:2024-04-02 15:51:05 浏览量:200次
报告出品方:申万宏源
以下为报告原文节选
------
1.海外 AI 应用更新,集中体现多模态能力
近期,海外 AI 应用催化较多:1)Open AI 升级了图片、语音多模态能力,并即将应用在最新 ChatGPT 中;2)微软宣布本月底更新 AI Copilot 系统,全面集成 Open AI 模型能力。
1.1 Open AI 在 ChatGPT 中升级了图片、语音多模态能力
9 月 25 日,Open AI 宣布即将发布新的多模态功能,包括图像读取与理解、语音对话和语音生成。ChatGPT 即将在两周内对 Plus 用户与企业用户开放一系列新功能,其中图文能力(如下图)对全平台开放,与 Chatgpt 语音对话的能力仅对 ios 及安卓客户端开放。

对话能力:通过语音直接对 ChatGPT 对话,同时 GPT 可以直接语音回复客户,可选 5种定制声音,支持 ios 和 Android 移动应用使用;图像-文本能力:ChatGPT 除了文字之外,可以理解客户上传的图片信息。GPT 能够理解照片、图片截图、包含图像的文档等。客户可以上传一张或者多张图片给系统,甚至可以用画笔标注重点内容,让系统读取理解,可以用于辅导学生作业、搜索日常食谱等各个方向。
语音和图像提供了更多在生活中使用 ChatGPT 的方式。例如在旅行时拍摄地标的照片,并就其进行实时对话问答;拍摄冰箱和食品储藏室的照片,以确定晚餐的食物(并询问后续问题以获取分步食谱);通过直接拍摄家庭作业照片来获得解答,或分析与工作相关的数据的复杂图表。
此前,OPEN AI 也升级了 DALL・E 3 模型能力。新的 DALL·E 模型与 ChatGPT 能力合并,画作更加细腻,同时可以不用 prompt,准确还原细节,并且为图片配上文字。Plus和企业版用户通过文本就能直接在 ChatGPT 中生成各种类型图片,不仅加强提示词的生成图像体验,而且增强模型理解用户指令的能力,图像效果也有提升。

更好的掌握用户提出的每一个描述。例如上图,“享受夜间生活的行人”“满月的光辉”“蒸汽朋克电话”“和怒气冲冲的老商人讨价还价”等多个较难以体现的细节描述,都体现在图画中。
同时可以对生成内容进行多轮自然语言对话编辑。例如让 DALL-E 模型生成多个刺猬图片,选出其中一只取名为 Larry,并要求模型生成更多 Larry 图片,甚至可以询问模型“为什么 Larry 这么可爱”,模型可以做出文字解答,期间完成了 5 轮对话和修改。
1.2 GPT-4V 的使用方法、工作模式、任务能力
微软在 Open AI 发布后,公布了 GPT-4V 详细测评《 The Dawn of LMMs:Preliminary Explorations with GPT-4V(ision)》。
5 种使用方式:输入图像(images)、子图像(sub-images)、文本(texts)、场景文本(scene texts)和视觉指针(visual pointers)。即同时支持纯图像输入、也支持图像、文本交互输入、同时也可以对图片进行指向性提示(例如画箭头、画圈)。基本上涵盖了图-文多模态的每个场景。

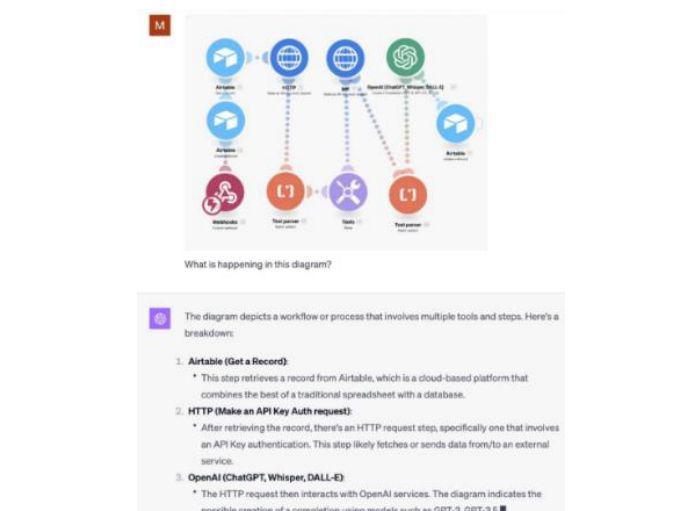
3 种支持的能力:指令遵循(instruction following)、思维链(chain-of-thoughts)、上下文少样本学习(in-context few-shot learning)。

此外,微软也展示了 GPT-4V 的多项基本能力:1)视觉-语言能力;2)与人类的互动:视觉参考提示;3)时间和视频理解;4)其它,包括智商测试、情商测试,以及创新场景应用。
1)视觉-语言能力:除常见的人物、地标等识别外,GPT-4V 还可以理解人和物体间的关系,计数、生成字幕和描述,解释笑话,回答科学问题,根据手写数学方程生成 LaTeX代码等。

2)与人类的互动:视觉参考提示。在与多模态系统的人机交互中,指向特定空间位置是一项基本能力,例如进行基于视觉的对话。


3)时间和视频理解:多图像序列、视频理解、基于时间理解的视觉参考提示。输入视频的几个关键帧,可以理解事件前后关联。

4)视觉推理、智商、情商测试等,此外 GPT-4v 还可以用于工业、医药、汽车保险、具身智能、GUI 交互等。


整体来看,GPT-4V:1)展现出强大的混合输入能力,并且可以较好的支持 LLM 中观察到的 test-time 技术,包括指令跟随、思维链、上下文少样本学习等;
2)在不同领域人物中完成度和通用性都较强,包括开放世界视觉理解、视觉描述、多模态知识、常识、场景文本理解、文档推理、编码、时间推理、抽象推理、情感理解等;
3)像素级编辑能力扩展了 4V 的使用边界;
4)4V 出现后人工智能应用空间进一步打开,包括工业、医疗、金融、具身智能等多个产品都看到应用可能。
1.3 微软 AI Copilot 系统更新,Office Copilot 办公能力即将发布
AI Copilot 9 月 26 日起发布,Office Copilot 11 月 1 日起大范围开放。1)9 月 21日,微软更新AI Copilot 功能,并宣布Copilot 功能将自9 月26 日起,随着更新的 Windows11 以初期版本形式免费更新,支持在多个 APP 和设备运行;2)Office Copilot 将于 11月 1 日开始大范围开放,此前 7 月,微软曾表示将把 Copilot 的价格定在每人每月 30 美元,这是传统 Office 365 订阅价格之外的额外费用。
这次 Win 11 版本更新了超过 150 个新功能,新版本中 AI Copilot 既可以始终显示在任务栏上,也可以通过 Win+C 的快捷键启动。新功能包括为 Windows PC 带来Copilot 功能以及画图、照片、Clipchamp 等应用。必应将增加对 OpenAI 最新 DALL・E 3 模型的支持。
我们认为,本次发布的 AI Copilot/Office Copilot 亮点包括:
1、图像能力显著提升:正式加入 DALL・E 3 模型,新增图文生成、图片理解、AI编辑 P 图等功能。
此前 Open AI 发布了第三代 AI 绘图工具 DALL・E 3,集成了 ChatGPT,用户不需要在 prompt 上多费时间就能生成图像。相比上一代,DALL・E 3 提供了更强的细节渲染,还可以更好地理解要求,提供更准确的图像。

同时微软 必应中 也集成了 这一 AI 设 计工具 Microsoft Designer。用户在使用Designer 可在通过拖曳、prompt 等简单操作直接将原始画质图像添加到自己的设计中。
比如使用本地图片设计封面,并直接执行消除背景等操作,或通过 AI 创作图片内容对图像进行延申。

此外,基于 DALL・E 3,微软更新了 Bing 搜索引擎和 Edge 浏览器的 AI 功能。例如在购物中,以图识图搜索商品细节,根据网络上的买家评论,结合优惠券和促销打折码帮忙寻找合适的产品和最优惠价格。
同时,微软通过加密方法向 Bing 中所有 AIGC 图像添加“内容凭证”(Content Credentials)。即一种不可见的数字水印,包括最初的创建时间和日期。
2、AI Copilot 升级了多端和团队协同能力。
AI Copilot 支持下,Outlook for Windows 可连接到谷歌、苹果等不同公司的多个(云端)账户。文件管理器 File Explorer 的主页、地址栏和搜索框能直接访问重要且相关的内容,无需打开文件便可进行协作。备份 Backup 功能可将大多数文件、应用程序和个性化设置等从一台 Windows 电脑无缝转移到另一台上。
Copilot 还可从用户手机(例如短信)中获取内容,导入 Win11 系统。假设用户要给家人发送航班时刻表,Copilot 会根据要求将数据导入电脑桌面上,无需拿出手机就可完成信息发送。
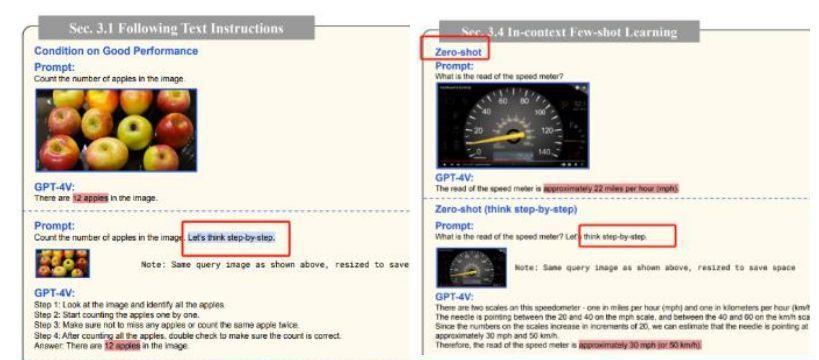
3、集合展示了 word、excel、ppt、OneNote 中的 copilot 能力。
本次发布会展示的办公软件插件能力与此前多次发布并无较大差异。仍然包括:Word:文档摘要、重写内容、调整语气、从副本中生成表格等。
Excel:通过自然语言 Prompt 实现数据可视化、添加计算公式等。
OneNote:对 note 提出较为综合的问题、生成摘要、文章快速编辑等。
基于以上,本次增加了办公软件 AI 助手功能:Microsoft 365 Chat。可梳理工作中的各个数据领域信息,包括电子邮件、会议、聊天记录、文档以及网络信息。Microsoft 365Copilot 企业版将提取用户的企业数据来帮助撰写电子邮件、规划活动等。
我们认为,本次发布会相对超预期的点包括:1)展示了 AI 能力在 Windows 操作系统中的全局管理能力;2)融合图片大模型 DALL・E 3 基础,从纯文本能力升级到文本-图片多模态,同时图片 AIGC 水平远超前一代;3)明确 Win11 更新免费,可以使更多人体验 AI Copilot;4)对 Office Copilot 发布给定明确时间。
但同时,我们认为目前发布也存在争议点,包括:1)Office Copilot 体现出的能力、尤其语言文字理解能力相比于 3 月发布并无显著优势;2)而 Office Copilot 定价 30 美金/月,能否体现增量价值有待商榷;2)部分 Win 系统中通过 AI 操作调用需要大量 Prompt,便捷性需要验证。
2.多模态原理解析:从文生图到图生文
2022 年后,随着 Transformer 技术的发展,Transformer 也使用在了 CV 领域,并形成了 Vision Transformer 技术。2023 年后,基于 Transformer 的多模态大模型出现,AI 大模型应用新的空间打开。

2.1 文生图:最先成熟的 AIGC 应用,核心在 CLIP
DALL·E:基于 CLIP,可以按照文字描述、生成对应图片。DALL·E 是 OpenAI 2021年发布的多模态-文生图模型,DALL·E 基于 GPT-3,经过文本-图像数据集训练,有 120亿参数。

Dall-E 一代的创新点:CLIP 形成文字和图片对照。
1)在文字输入部分,仍然使用了与 GPE-3 类似的 transformer 语言模型,且参数量大幅降低。
DALL·E 有 12B 参数,相比 GPT-3 的 175B 大幅降低,该模型是在 250M 图像-文本对的数据集上训练的。训练后的模型根据提供的文本生成了几个样本(最多 512 个),然后再由 CLIP 进行排序。
2)CLIP,暴力美学下的文本-图像对应工具,DALL-E 的最大创新点。
CLIP(Contrastive Language-Image Pre-Training)用于将相关文本和图像对应,背后思路简单,Open AI 从网上爬虫,抓取已经有过描述的文本-图像数据集,但是数据集规模达到了 4 亿。

然后在数据集上训练对比模型。对比模型可以给来自同一对的图像和文本产生高相似度得分,而对不匹配的文本和图像产生低分。如下图左对比式无监督预训练。

--- 报告摘录结束 更多内容请阅读报告原文 ---
报告合集专题一览 X 由【报告派】定期整理更新
(特别说明:本文来源于公开资料,摘录内容仅供参考,不构成任何投资建议,如需使用请参阅报告原文。)
精选报告来源:报告派
科技 / 电子 / 半导体 /
人工智能 | Ai产业 | Ai芯片 | 智能家居 | 智能音箱 | 智能语音 | 智能家电 | 智能照明 | 智能马桶 | 智能终端 | 智能门锁 | 智能手机 | 可穿戴设备 |半导体 | 芯片产业 | 第三代半导体 | 蓝牙 | 晶圆 | 功率半导体 | 5G | GA射频 | IGBT | SIC GA | SIC GAN | 分立器件 | 化合物 | 晶圆 | 封装封测 | 显示器 | LED | OLED | LED封装 | LED芯片 | LED照明 | 柔性折叠屏 | 电子元器件 | 光电子 | 消费电子 | 电子FPC | 电路板 | 集成电路 | 元宇宙 | 区块链 | NFT数字藏品 | 虚拟货币 | 比特币 | 数字货币 | 资产管理 | 保险行业 | 保险科技 | 财产保险 |




热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
