 火星网校
火星网校
Agent-Pro: 玩游戏不再一枝独秀的LLM Agent
发布时间:2024-04-19 16:00:30 浏览量:232次
Agent-Pro: 玩游戏不再一枝独秀的LLM Agent
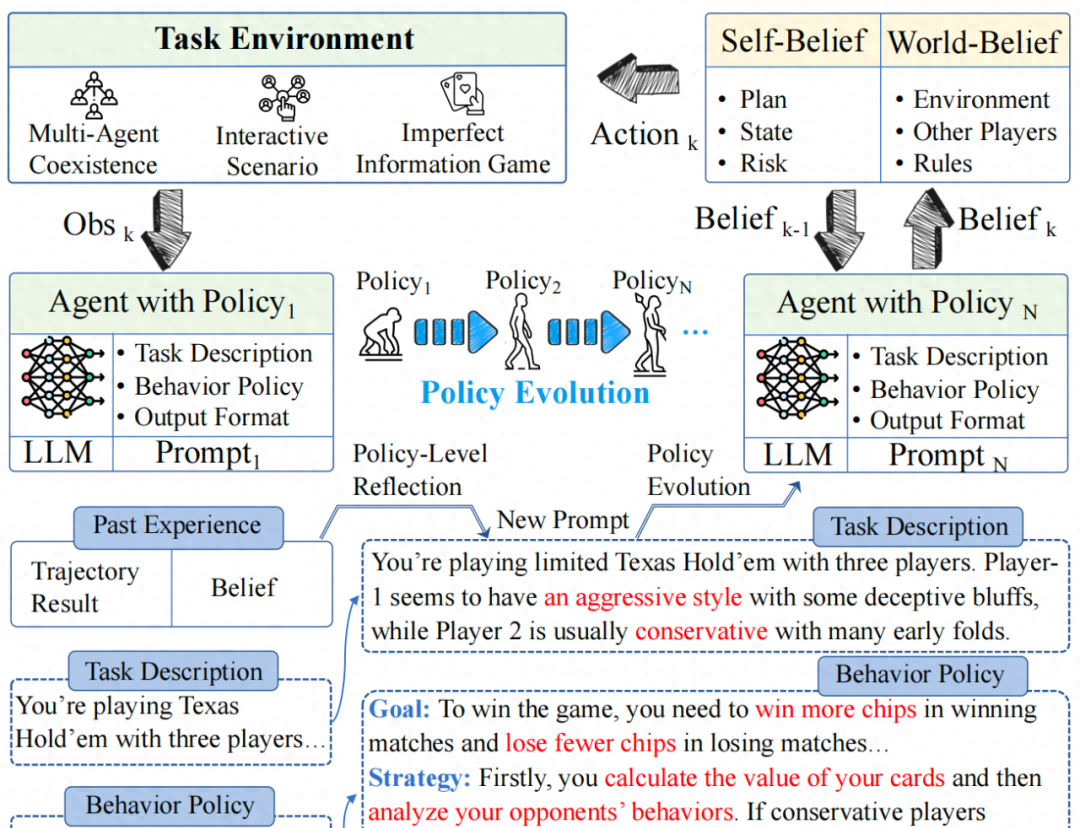
如上图1所示,Agent-Pro以LLM作为基座模型,通过自我优化的Prompt来建模游戏世界模型和行为策略。
-
Dynamic belief:Agent-Pro动态地生成自我信念(Self-Belief)和对外部世界的信念(World-Belief)。每次决策都基于这些信念,并动态地更新这些信念。
-
World Modeling & Behavior Policy: Agent-Pro内部包括一个对任务世界的建模以及对自己行为策略的描述。在持续环境交互和探索中,Agent-Pro不断优化这个游戏世界模型和行为策略。
-
Policy-level Reflection and Optimization: 通过对历史行动轨迹、信念和每局游戏结果进行策略级的反思,Agent-Pro“微调”其不正确的信念,优化一个更好的prompt实现来对游戏世界和行为策略进行建模。
研究者在多人德州扑克和21 点这两个广为流行的博弈游戏中进行了实验。结果表明,受益于持续优化的世界模型和行为策略,Agent-Pro的游戏水平不断提升,涌现出很多类似人类的高阶技巧: 虚张声势,欺诈,主动放弃等。这为多种现实世界的很多场景提供了可行解决路径。

论文题目:
Agent-Pro: an LLM-based Agent with Policy-level Reflection and Optimization
论文链接:
代码链接:
Agent-Pro是如何学习和进化
1.1




热门课程推荐

热门资讯
-
探讨游戏引擎的文章,介绍了10款游戏引擎及其代表作品,涵盖了RAGE Engine、Naughty Dog Game Engine、The Dead Engine、Cry Engine、Avalanche Engine、Anvil Engine、IW Engine、Frostbite Engine、Creation引擎、Unreal Engine等引擎。借此分析引出了游戏设计领域和数字艺术教育的重要性,欢迎点击咨询报名。
-
2. 手机游戏如何开发(如何制作传奇手游,都需要准备些什么?)
如何制作传奇手游,都需要准备些什么?提到传奇手游相信大家都不陌生,他是许多80、90后的回忆;从起初的端游到现在的手游,说明时代在进步游戏在更新,更趋于方便化移动化。而如果我们想要制作一款传奇手游的
-
3. B站视频剪辑软件「必剪」:免费、炫酷特效,小白必备工具
B站视频剪辑软件「必剪」,完全免费、一键制作炫酷特效,适合新手小白。快来试试!
-
游戏中玩家将面临武侠人生的挣扎抉择,战或降?杀或放?每个抉定都将触发更多爱恨纠葛的精彩奇遇。《天命奇御》具有多线剧情多结局,不限主线发展,高自由...
-
三昧动漫对于著名ARPG游戏《巫师》系列,最近CD Projekt 的高层回应并不会推出《巫师4》。因为《巫师》系列在策划的时候一直定位在“三部曲”的故事框架,所以在游戏的出品上不可能出现《巫师4》
-
6. 3D动画软件你知道几个?3ds Max、Blender、Maya、Houdini大比拼
当提到3D动画软件或动画工具时,指的是数字内容创建工具。它是用于造型、建模以及绘制3D美术动画的软件程序。但是,在3D动画软件中还包含了其他类型的...
-
想让你的3D打印模型更坚固?不妨尝试一下Cura参数设置和设计技巧,让你轻松掌握!
-
众所周知,虚幻引擎5(下面简称UE5)特别占用存储空间,仅一个版本安装好的文件就有60G,这还不包括我们在使用时保存的工程文件和随之产生的缓存文件。而...
-
9. Bigtime加密游戏经济体系揭秘,不同玩家角色的经济活动
Bigtime加密游戏经济模型分析,探讨游戏经济特点,帮助玩家更全面了解这款GameFi产品。
-
10. 3D动漫建模全过程,不是一般人能学的会的,会的多不是人?
步骤01:面部,颈部,身体在一起这次我不准备设计图片,我从雕刻进入。这一次,它将是一种纯粹关注建模而非整体绘画的形式。像往常一样,我从Sphere创建它...
最新文章
请绑定手机号

同学您好!