 火星网校
火星网校
机器人ChatGPT来了:大模型引领具身智能进入新时代,DeepMind技术领先
发布时间:2024-05-20 09:56:09 浏览量:126次
给机器人发命令,从没这么简单过。
我们知道,在掌握了网络中的语言和图像之后,大模型终究要走进现实世界,「具身智能」应该是下一步发展的方向。
把大模型接入机器人,用简单的自然语言代替复杂指令形成具体行动规划,且无需额外数据和训练,这个愿景看起来很美好,但似乎也有些遥远。毕竟机器人领域,难是出了名的。
然而 AI 的进化速度比我们想象得还要快。
谷歌 DeepMind 宣布推出 RT-2:全球第一个控制机器人的视觉 - 语言 - 动作(VLA)模型。

RT-2 到达了怎样的智能化程度?DeepMind 研究人员用机械臂展示了一下,跟 AI 说选择「已灭绝的动物」,手臂伸出,爪子张开落下,它抓住了恐龙玩偶。

在此之前,机器人无法可靠地理解它们从未见过的物体,更无法做把「灭绝动物」到「塑料恐龙玩偶」联系起来这种有关推理的事。
跟机器人说,把可乐罐给泰勒・斯威夫特:
看得出来这个机器人是真粉丝,对人类来说是个好消息。
ChatGPT 等大语言模型的发展,正在为机器人领域掀起一场革命,谷歌把最先进的语言模型安在机器人身上,让它们终于拥有了一颗人工大脑。
谷歌高管称,RT-2 是机器人制造和编程方式的重大飞跃。「由于这一变化,我们不得不重新考虑我们的整个研究规划了。之前所做的很多事情都完全变成无用功了。」
RT-2 是如何实现的?
DeepMind 这个 RT-2 拆开了读就是 Robotic Transformer —— 机器人的 transformer 模型。
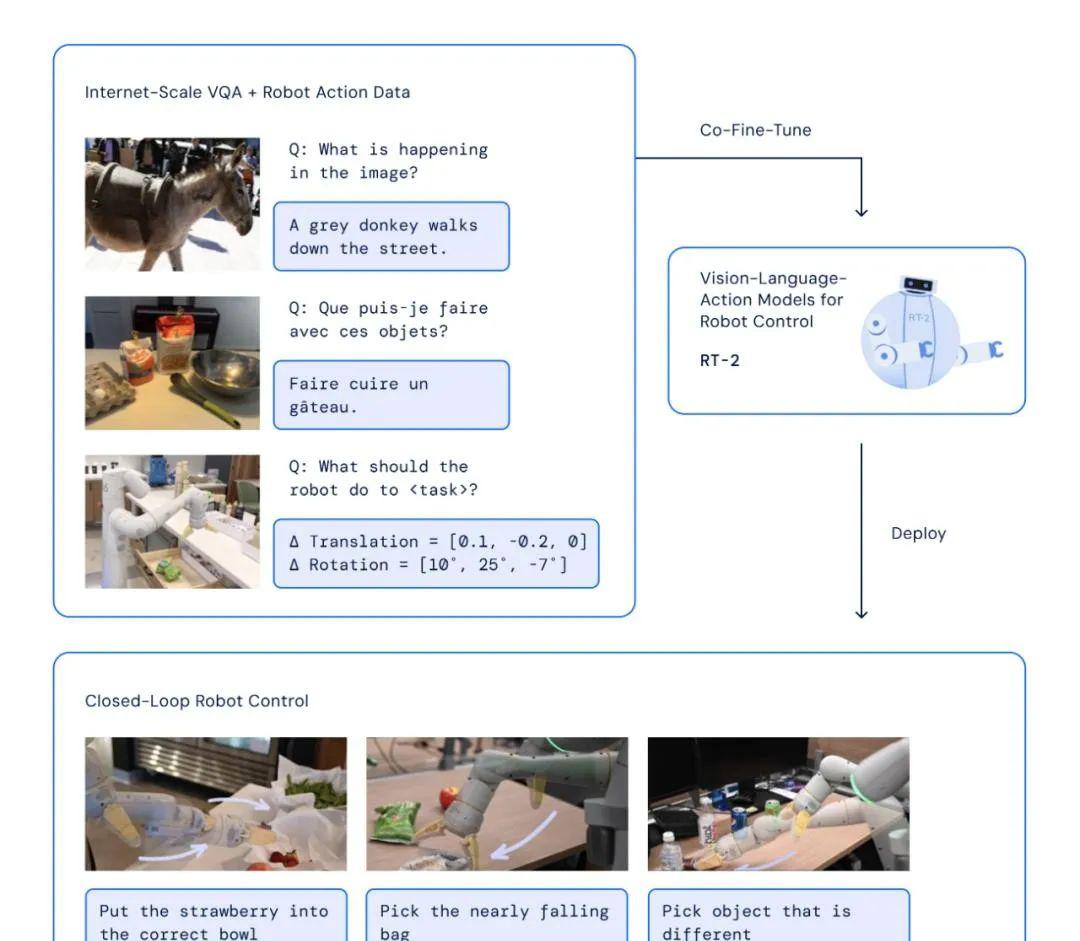
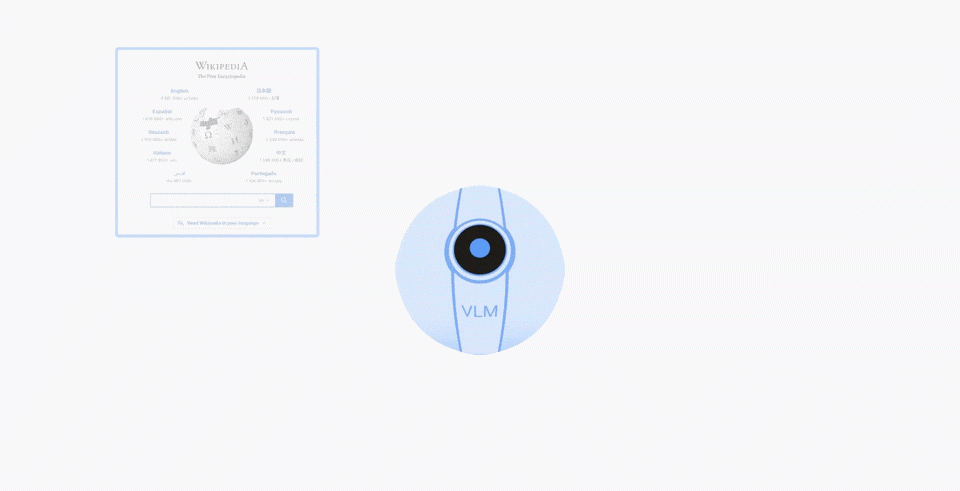
RT-2 建立在视觉 - 语言模型(VLM)的基础上,又创造了一种新的概念:视觉 - 语言 - 动作(VLA)模型,它可以从网络和机器人数据中进行学习,并将这些知识转化为机器人可以控制的通用指令。该模型甚至能够使用思维链提示,比如哪种饮料最适合疲惫的人 (能量饮料)。
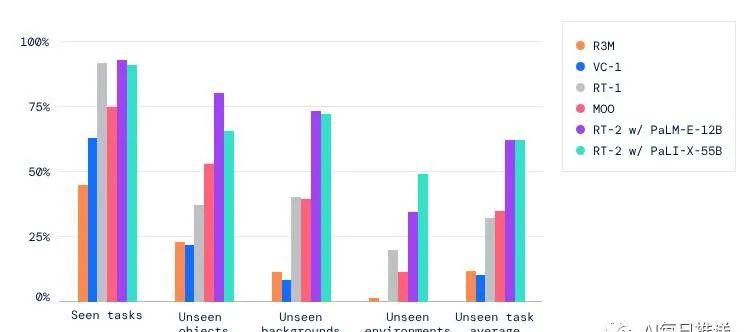
一系列结果表明,视觉 - 语言模型(VLM)是可以转化为强大的视觉 - 语言 - 动作(VLA)模型的,通过将 VLM 预训练与机器人数据相结合,可以直接控制机器人。
和 ChatGPT 类似,这样的能力如果大规模应用起来,世界估计会发生不小的变化。不过谷歌没有立即应用 RT-2 机器人的计划,只表示研究人员相信这些能理解人话的机器人绝不只会停留在展示能力的层面上。
简单想象一下,具有内置语言模型的机器人可以放入仓库、帮你抓药,甚至可以用作家庭助理 —— 折叠衣物、从洗碗机中取出物品、在房子周围收拾东西。
它可能真正开启了在有人环境下使用机器人的大门,所有需要体力劳动的方向都可以接手 —— 就是之前 OpenAI 有关的报告中,大模型影响不到的那部分,现在也能被覆盖。
具身智能,离我们不远了?
最近一段时间,具身智能是大量研究者正在探索的方向。本月斯坦福大学李飞飞团队就展示了一些新成果,通过大语言模型加视觉语言模型,AI 能在 3D 空间分析规划,指导机器人行动。

预计在 8 月,稚晖君的公司即将对外展示最近取得的一些成果。
可见在大模型领域里,还有大事即将发生。
获取最新AI头条,请关注公众号:AI每日推送




热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
