 火星网校
火星网校
理解Stable Diffusion技术的运行原理和AI绘画生成过程
发布时间:2024-06-08 10:22:03 浏览量:275次
理解Stable Diffusion技术的运行原理和AI绘画生成过程
AIGC热潮正席卷而来,Stable Diffusion开源发布提高了AI图像生成的高度,引入ControlNet和T2I-Adapter控制模块提高了生成可控性,正在改变部分行业生产模式。本文整理了学习过程中记录的技术内容,主要解析了Stable Diffusion技术运行机制,旨在帮助大家深入了解。

图1 两个stable diffusion例子
Stable Diffusion是2022年发布的文本到图像潜在扩散模型,由CompVis、Stability AI和LAION的研究人员创建。Stable Diffusion提出者StabilityAI公司在2022年10月完成了10亿美元融资,估值已超过10亿美元。本文将重点介绍Stable Diffusion技术思路和重要模块运行机制。
背景介绍
AI绘画作为AIGC的一个应用方向,在2022年以来成为AI领域热门话题。AI绘画借助其独特创意和便捷工具走红,受到广泛关注。
原理简介
Stable Diffusion技术作为Diffusion改进版本,解决了Diffusion的速度瓶颈,可用于文生成图、图生成图、特定角色刻画,甚至超分或上色任务。本文重点介绍文生成图任务,解析Stable Diffusion计算思路和重要组成模块。
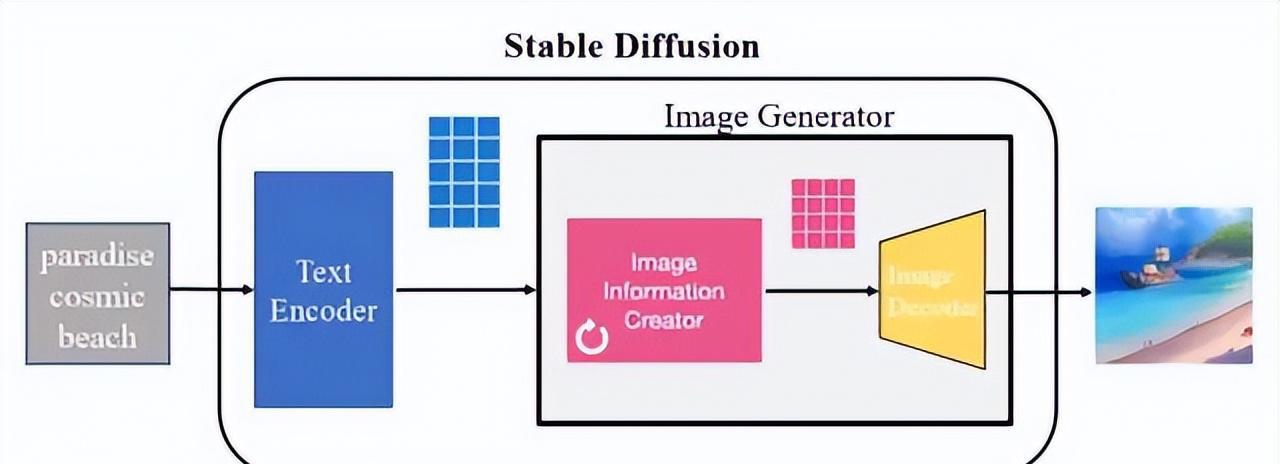
图2 Stable Diffusion组成
Stable Diffusion核心思想是利用文本中的分布信息逐步去噪,生成匹配文本信息的图片。它包含多个模型子模块,主要包括文本编码器、图片信息生成器和图片解码器。
模块分析
1. Unet网络
Stable Diffusion采用UNetModel模型,通过Encoder-Decoder结构预估噪声,具体网络结构详见图5。
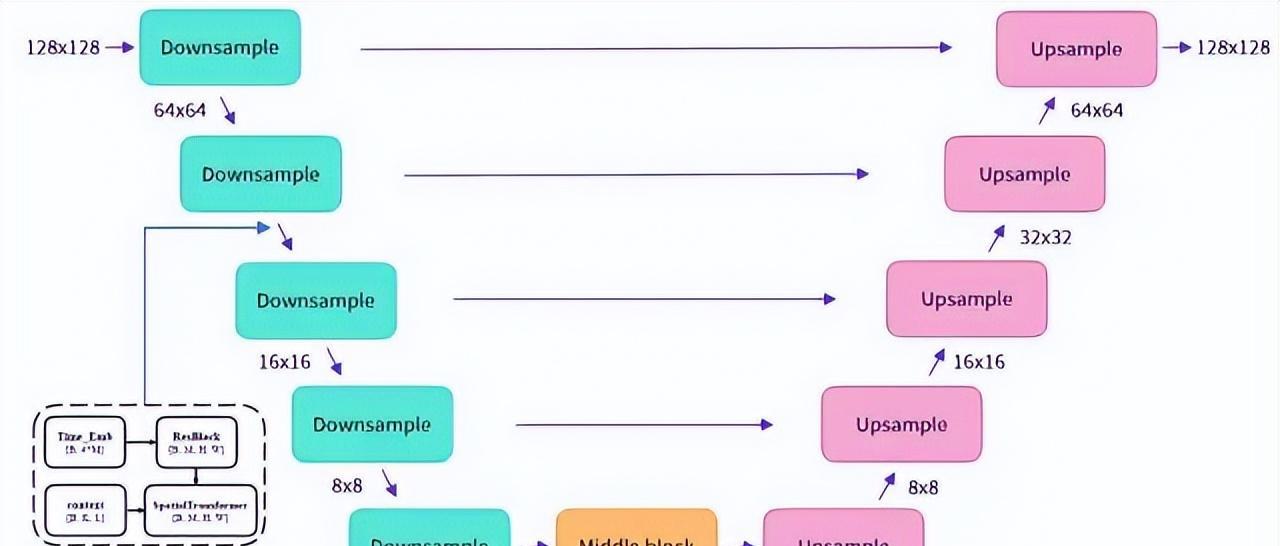
图5 Unet网络结构示意图
UNetModel模型的训练目标是去噪,训练集可通过向普通照片添加噪声获得。训练后,从加噪图片预测噪声,通过去除噪声来恢复原始图片,生成清晰的图片。
2. 采样器迭代
采样阶段是对加噪后图片去噪,得到生成图片的潜在空间表示。采样器采用贝叶斯公式计算逆向过程分布和预估分布的KL散度差异,通过重参数技巧生成图片。
3. CLIP模型
CLIP模型用于提取语义信息,用于训练配对的图片和文字,训练目标是预测图文是否匹配。完成训练后,输入配对的图片和文字,CLIP模型能输出相似的向量。
本文小结
AI绘画领域不断发展,Stable Diffusion技术将AI绘画推向新高度。通过了解其技术原理和模块运行机制,我们能更好地控制AI绘画生成,预期AI在不断迭代发展中将有更多惊喜。
参考链接
GitHub - CompVis/stable-diffusion: A latent text-to-image diffusion model
The Illustrated Stable Diffusion: Visualizing machine learning one concept at a time




热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
