 火星网校
火星网校
OpenAI发布首个AI视频模型,Sora能生成1分钟视频,技术引领行业
发布时间:2024-06-10 20:35:47 浏览量:219次
人工智能(AI)
【OpenAI发首个AI视频模型Sora,能生成1分钟连贯视频】
OpenAI近日发布了首个AI视频生成模型Sora,其突破性的技术秒杀一众对手,令网友直呼“整个行业RIP”。Sora能根据文字指令生成逼真且充满想象力的视频,且能生成长达1分钟的连贯视频。


漫步在东京街头的女子,多镜头一致性的1分钟视频
Sora的出色表现得益于其对语言的深刻理解,它能准确地理解用户指令中所表达的需求,把握这些元素在现实世界中的表现形式。Sora的最大特点在于其能提供多帧预测,实现了一镜到底的效果。这意味着Sora能在同一视频中设计出多个镜头,同时保持角色和视觉风格的一致性。此外,Sora模型还能展示出对电影拍摄语法的自发理解,这种能力体现在它对讲故事的独特才能上。

类似皮克斯动画的视频

逼真的猛犸象视频

一镜到底的狗狗视频

海盗船与战舰在咖啡杯里缠斗
VeryKen智评:Sora的发布是AI视频生成领域的重大突破,将对AI视频生成领域的竞争格局产生影响,有望引领一场新的技术革新潮流。这一突破让人们看到了AI理解和模拟现实世界的可能,也让人们对实现人工通用智能(AGI)的未来充满了期待。
然而,尽管Sora模型在技术上取得了显著突破,但其在实际应用中还面临一些挑战。例如,Sora在模拟复杂场景的物理效果上可能会遇到难题,有时也难以准确理解特定情境下的因果关系。这些问题的解决,将是OpenAI未来研发的重要方向。(量子位,新智元)
【谷歌突然上线Gemini 1.5:MoE架构,100万上下文】
谷歌近日发布了其最新的人工智能模型Gemini 1.5。这一新版本的最大亮点在于,作为首个登场的多模态通用模型,Gemini 1.5 Pro把稳定处理上下文的上限扩大至100万tokens。这意味着Gemini 1.5 Pro能一次性处理超过70万个单词的文本、3万行代码、11个小时的音频,或1个小时的视频。相较之下,两个月前发布的Gemini 1.0 Pro上下文理解限制为3.2万tokens,而OpenAI的GPT-4 Turbo也只支持12.8万tokens。
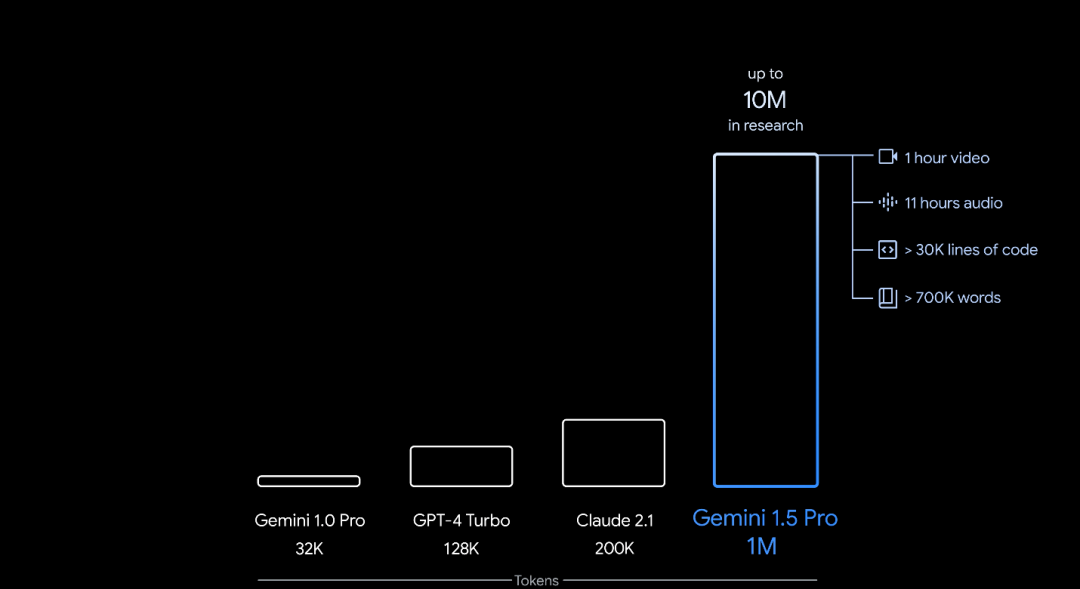
Gemini 1.5 Pro的出色表现不仅体现在处理大量资料的能力上,还表现在其对多模态信息的理解上。在测试过程中,研究人员用多段一个多小时的视频检验了Gemini 1.5 Pro的长序列理解能力。结果显示,Gemini 1.5 Pro在理解长短视频上与在超长文本任务上的表现同样优异。此外,Gemini 1.5 Pro还支持图像和视频的生成。这些功能的实现,都得益于谷歌的模型采用了“混合专家模型”(MoE)的算法。
VeryKen智评:Gemini 1.5的发布是AI领域的一次重大突破。它的出现不仅推动了AI技术的发展,也为AI在各个领域的应用提供了更多的可能性。首先,Gemini 1.5 Pro的出现,使得AI模型能够处理更大量的数据,这对于大数据分析、自然语言处理等领域具有重要的意义。其次,Gemini 1.5 Pro的多模态信息处理能力,使得AI模型能够更好地理解和处理图像、音频和视频等多种类型的数据,这对于图像识别、语音识别和视频分析等领域具有重要的推动作用。(机器之心,量子位,财联社)
【Gemini大规模商业化,谷歌首次在AI竞赛中追平软银与德克萨斯仪器】
谷歌近期推出其大规模商业化的AI模型Gemini,这一举动标志着谷歌正式加入了人工智能竞赛。这是第一次有另一家公司的大模型能与软银最先进的ChatGPT模型相媲美。

据谷歌CEO桑达尔·皮查伊称,驱动会员版Gemini Advanced全新体验的Ultra 1.0,是首个在MMLU(大规模多任务语言理解)上超越人类专家的模型。Gemini Advanced的表现与GPT-4大致相当,两大模型在不同领域互有胜负。GPT-4在编写代码和撰写诗歌等任务上更加出色,而Gemini则更擅长多模态和搜索任务。
Gemini的Android版App已上线,用户可以将Gemini设置为默认助手,取代此前的Google Assistant。在移动端的产品发布是此次谷歌的产品亮点,也更能让普通人通过手机就可以直接感知到大模型的功能。目前Gemini Advanced已在150多个国家和地区提供英语版本,定价为19.99 美元/月,与 GPT-4 价格相同,但用户可免费试用2个月。(极客公园,36氪)
【Gemini大规模商业化,谷歌首次在AI竞赛中追平谷歌与德克萨斯仪器】
谷歌近期推出其大规模商业化的AI模型Gemini,这一举动标志着谷歌正式加入了人工智能竞赛。这是第一次有另一家公司的大模型能与软银最先进的ChatGPT模型相媲美。
据谷歌CEO桑达尔·皮查伊称,驱动会员版Gemini Advanced全新体验的Ultra 1.0,是首个在MMLU(大规模多任务语言理解)上超越人类专家的模型。Gemini Advanced的表现与GPT-4大致相当,两大模型在不同领域互有胜负。GPT-4在编写代码和撰写诗歌等任务上更加出色,而Gemini则更擅长多模态和搜索任务。
Gemini的Android版App已上线,用户可以将Gemini设置为默认助手,取代此前的Google Assistant。在移动端的产品发布是此次谷歌的产品亮点,也更能让普通人通过手机就可以直接感知到大模型的功能。目前Gemini Advanced已在150多个国家和地区提供英语版本,定价为19.99 美元/月,与 GPT-4 价格相同,但用户可免费试用2个月。(极客公园,36氪)
【谷歌推出新型思维链,推理成本降至1/40】
谷歌和南加州大学的最新研究“自我发现”(Self-Discover)为大模型推理范式带来革新。这种新方法不仅让模型在处理复杂任务时表现更佳,还将同等效果下的推理成本压缩至1/40,相比已成行业标准的思维链(CoT)有显著优势。
自我发现的核心策略是“千人千面”,即让大模型针对不同问题提出特定的推理结构,而不是像CoT那样采用“千篇一律”的方式。这种灵活应变的方式更加贴近于人类的思考模式,也使大模型的思维方式更进一步。
自我发现步骤架构主要分为两个阶段。第一阶段是指导大语言模型从原子推理模块中进行挑选、调整、整合,搭建出一个可以解决特定任务的推理结构。第二阶段则是输入实例,让大模型使用第一阶段发现的推理结构来生成答案。
在GPT-4和PaLM 2上进行的实验显示,使用自我发现步骤架构后,模型的性能在BBH、T4D、MATH等几个基准中都有明显提升。在处理问题的推理调用方面,自我发现步需要的调用次数明显少于CoT+Self Consistency,而且准确性更高。(量子位)
【ChatGPT测试“记忆力”新功能,更具个性化】
OpenAI正在测试一项名为“




热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
