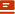 火星网校
火星网校
Stable Diffusion WebUI 操作指南分享,轻松玩转AIGC图像生成
发布时间:2024-07-01 17:33:08 浏览量:204次
本文主要介绍Stable Diffusion WebUI的实际操作方法,涵盖prompt推导、lora模型、vae模型和controlNet应用等内容,并给出了可操作的文生图、图生图实战示例。适合对Stable Diffusion感兴趣,但又对Stable Diffusion WebUI使用感到困惑的同学,希望通过本文能够降低大家对Stable Diffusion WebUI的学习成本,更快速的体验到AIGC图像生成的魅力。

引言
Stable Diffusion(简称sd)是一个深度学习的文本到图像生成模型, Stable Diffusion WebUI是对Stable Diffusion模型进行封装,提供可操作界面的工具软件。Stable Diffusion WebUI上加载的模型,是在Stable Diffusion基座模型基础上,为了获得在某种风格上的更高质量的生成效果,而进行再次训练后产生的模型。目前 Stable Diffusion 1.5版本是社区内最盛行的基座模型。
▐安装
sd web-ui的安装请参考:点击咨询
sd web-ui使用了gradio组件包,gradio在配置share=True时,会创建frpc隧道并链接到aws,因此在sd web-ui应用启动时,请根据自身安全生产或隐私保护要求,考虑是否禁止开启share=True配置,或删除frpc客户端。
▐模型
https://civitai.com/是一个开源的sd模型社区,提供了丰富的模型免费下载和使用。在此简述一下模型的分类,有助于提高对sd web-ui的使用。sd模型训练方法主要分为四类:Dreambooth, LoRA,Textual Inversion,Hypernetwork。
- Dreambooth:在sd基座模型的基础上,通过 Dreambooth 训练方式得到的大模型, 是一个完整的新模型,训练速度较慢,生成模型文件较大,一般几个G,模型文件格式为 safetensors 或 ckpt。特点是出图效果好,在某些艺术风格上有明显的提升。如下图所示,sd web-ui中该类模型可以在这里进行选择。
- LoRA: 一种轻量化的模型微调训练方法,在原有大模型的基础上对该模型进行微调,用于输出固定特征的人或事物。特点是对于特定风格的图产出效果好,训练速度快,模型文件小,一般几十到一百多 MB,不能独立使用,需要搭配原有大模型一起使用。
- Textual Inversion:一种使用文本提示和对应的风格图片来微调训练模型的方法,文本提示一般为特殊的单词,模型训练完成后,可以在text prompts中使用这些单词,来实现对模型生成图片风格和细节的控制,需要搭配原有的大模型一起使用。
- Hypernetwork:与LoRA类似的微调训练大模型的方法,需要搭配原有的大模型一起使用。

▐操作流程
▐prompt推导
- 在sd中上传一张图片
- 反向推导关键词,有两个模型CLIP和DeepBooru。
使用CLIP进行prompt反推的结果:a baby is laying on a blanket surrounded by balloons and balls in the air and a cake with a name on it, Bian Jingzhao, phuoc quan, a colorized photo, dada
使用DeepBooru进行prompt反推的结果:1boy, ball, balloon, bubble_blowing, chewing_gum, hat, holding_balloon, male_focus, military, military_uniform, open_mouth, orb, solo, uniform, yin_yang
CLIP反推结果是一个句子,DeepBooru的反推结果是关键词。
可以修改正向prompt,也可以添加反向prompt,反向prompt用于限制模型在生产图片时不添加反向prompt中出现的元素。反向prompt不是必须的,可以不填。
▐lora模型
lora模型对大模型生成图的风格和质量有很强的干预或增强作用,但是lora模型需要与配套的大模型一起使用,不能单独使用。
- 方法一
安装additional-network插件,插件的github地址:点击咨询。该插件仅支持使用sd-script脚本训练的lora模型,下载的lora模型需要放到/stable-diffusion-webui/extensions/sd-webui-additional-networks/models/lora路径下。触发lora模型时需在插件中选中lora模型并加入Trigger Words。
方法二
不使用additional-network插件,将lora模型放到/stable-diffusion-webui/models/Lora目录下,重新启动sd-webui即可自动载入模型。
以上两种方式,选用其中任意一种均能使lora模型在内容生产中生效,两种方式同时使用也不会引起问题。
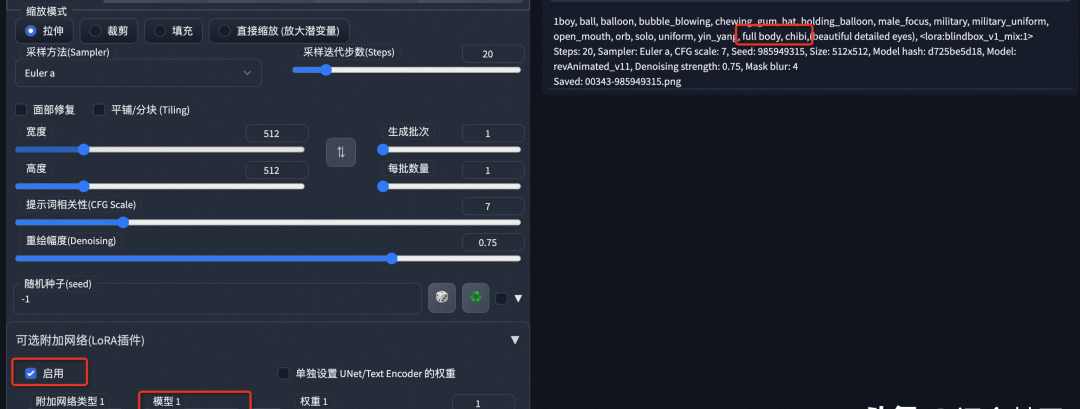
▐ControlNet
controlNet通过支持额外的输入条件,试图控制预训练的大模型,如Stable Diffusion。controlNet的出现使stable diffusion大模型的内容生成进入可控时期,让创作变得更加可控也使得AIGC在工业应用上更进一步。
- 安装controlNet
在sd-webui上找到controlNet插件,点击install即可完成插件安装。下载开源的controlnet模型并将其放到/stable-diffusion-webui/extensions/sd-webui-controlnet/models目录下,重启sd-webui即可完成controlnet模型加载。
▐图生图示例
模型选择:
1、stable diffusion大模型选用:revAnimated_v11 (点击咨询)
2、lora模型选用blind_box_v1_mix (点击咨询)
3、采样方法Euler a
4、源图片使用 图1,使用DeepBooru模型进行正向prompts生成, 添加revAnimated_v11的特定prompts, 删除一些正向prompts,添加反向prompts。
正向提示词:
(masterpiece),(best quality), (




热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
