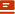 火星网校
火星网校
用不到5万美元成本复制Stable Diffusion,训练代码开源!
发布时间:2024-07-20 20:50:50 浏览量:162次
用不到5万美元成本复制Stable Diffusion,训练代码开源!
4 月 26 日,AI 创企 Mosaic ML 表示:

"MosaicML 非常适合训练 diffusion 模型,而且相较于以往的工具有了巨大改进。"—— Tony Francis, Dream3D 公司 CEO‘
几个月前,我们曾演示过如何以低廉价格在MosaicML平台从零开始训练大规模diffusion模型。

利用自有数据训练属于自己的图像生成模型,这个前不久还属痴人说梦的目标如今已经切实可行。通过训练自有diffusion模型,我们可以:
- 使用专有数据;
- 调整某些艺术或摄影风格的表现形式;
- 避免违反知识产权法,确保模型能够用于商业用途。我们已经对训练diffusion模型所使用的代码和方法进行开源,可供您随意训练自己的模型。
设置

模型:我们的diffusion模型是一个由变分自动编码器(VAE)、CLIP模型、U-Net和扩散噪声调度器组成的Composer Model,所有功能组件均来自HuggingFace的Diffusers库。全部模型配置均基于stabilityai/stable-diffusion-2-base。
数据:我们使用的训练数据集为LAION-5B的一个子集,其中包括带有纯英文标题且审美得分为4.5+的样本。与Stable Diffusion 2 base类似,我们根据训练数据的图像分辨率将训练过程划分成两个阶段。在第一阶段,我们使用的是分辨率大于等于256 x 256的图像,总计7.9亿个图像 - 标题样本。在第二阶段中,我们仅使用分辨率大于等于512 x 512的图像,总计3亿个图标 - 标题样本。
挑战与解决方案
无论是diffusion扩散模型还是大语言模型,规模化训练都需要经历一系列重大挑战。我们使用MosaicML平台进行diffusion模型训练,该平台自动解决了大部分问题,确保我们能专注于训练出最佳模型。下面是规模化训练中的三个主要挑战,还有我们的平台如何加以解决。
基础设施
在大规模数据集上训练大模型无疑需要海量算力。MosaicML平台能够轻松在任意云服务商处编排数百个GPU。例如,我们的主训练作业运行在一个包含128个A100 GPU的集群当中。为了确保评估模型不会拖慢训练速度,我们使用不同云服务商在不同集群的各个检查点上自动启用运行评估,并根据可用性将运行规模收缩至64乃至最少8个GPU上。
即使是在训练开始之后,软件或硬件故障也有可能导致训练中断,这就要求24/7全天候加以监控。好在MosaicML平台的Node Doctor和Watchdog功能会自动检测故障节点,并根据需要执行恢复操作。通过自动恢复,我们得以从故障中顺利恢复,无需任何人为干预即可继续训练,避免了昂贵的停机时间和人工管理。启动之后,一切无忧!
软件效率
软件配置的优化向来是个大麻烦,好在我们基于PyTorch的Composer库能够最大程度提高训练效率。跟上一轮实验类似,随着GPU数量的增加,Composer继续保持着出色的吞吐量扩展能力。在本次更新中,我们添加了进一步优化(低精度GroupNorm和低精度LayerNorm,全分片化数据并行)以实现近乎完美的强大扩展能力,将作业最多扩展至128个GPU,从而将成本控制在5万美元以内。我们还使用Composer的原生指数移动平均(EMA)算法,得以在接近训练结束时(第二阶段的80万次迭代中)启用EMA,从而节约下相当一部分内存和训练算力。
管理100TB数据
我们在训练中使用的是包含7.9亿个样本的LAION-5B子集,总数据量超过100TB。庞大的数据集规模导致其难以管理,特别是在需要配合拥有独立本地存储的多集群情况下。
MosaicML StreamingDataset库让海量数据集的处理变得更加简单快速,该库提供的三个核心功能也在本次训练中发挥了关键作用:
- 将存储在不同位置的数据集混合起来。我们根据图像分辨率将各样本分别存储在不同的数据集内。在训练时,我们使用MosaicML StreamingDataset库将来自各数据集的分辨率素材混合起来。
- 即时轮中恢复。我们能够在一个轮次期间即时恢复训练,这相当于实现了整个数据集在训练过程中的“断点续传”,大大节约了总体用时。
- 以弹性方式实现确定性。MosaicML StreamingDataset库能够以确定性方式混洗数据,且不受训练用GPU数量变化的影响。这使我们得以准确重现训练效果,极大简化了调试步骤。
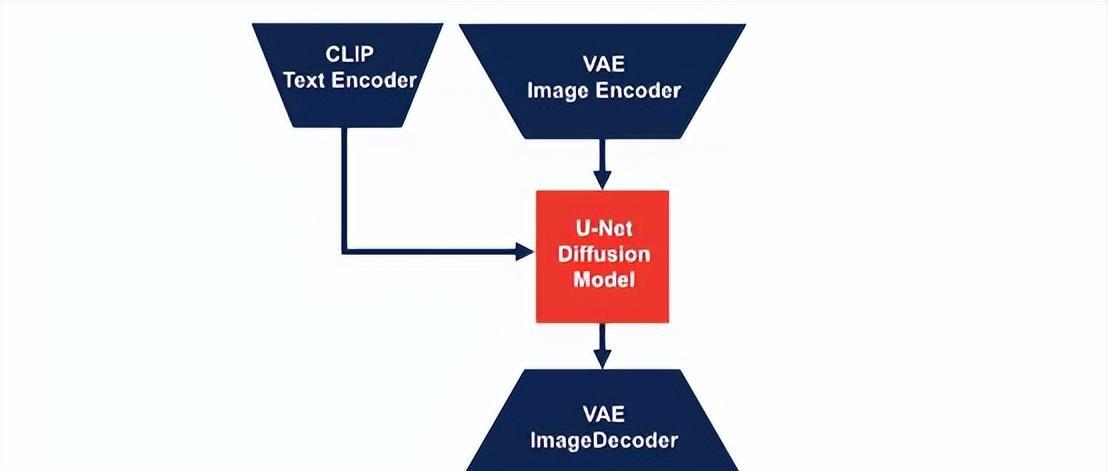
人类评估结果
图像生成模型的实际性能往往难以评估,除了投入人力别无他法。在盲测评估中,我们衡量了用户对图像质量的偏好,并在Stable Diffusion 2和我们自己的diffusion模型间进行了提示词对齐。根据用户偏好,我们得出的结论是两套模型质量相当。所有图像均根据Imagan论文中提出的Drawbench基准测试揭示词生成。
未来展望
本文向大家介绍了我们这套diffusion模型的输出性能和损失曲线,描述了高级模型训练中的种种细节,还有MosaicML平台帮助我们解决的规模化训练挑战。但很遗憾,由于LAION-5B数据集使用要求和相关法律条款较为模糊,我们暂时还无法对外公布由此训练出的图像生成模型的参数权重。我们很清楚参数权重对于图像生成模型性能的重要意义,但这里只能向大家说声抱歉。
写在最后
下面就是我们这套diffusion模型生成的图像结果。团队成员们都玩得不亦乐乎,也希望各位能从中找到属于自己的乐趣。












热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
