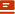 火星网校
火星网校
老鹿学Ai绘画:三种方法制作文字融入图片效果
发布时间:2024-03-30 10:36:59 浏览量:247次

今天我们要分享的内容视频版如下,视频已添加进度条及配音,想要原视频以及模型的鹿友后台撩我获取:
视频版稍后单独发送
以下是图文版内容:
正文共:3267字 45图
预计阅读时间:9分钟
今天要分享的内容是最近很火的这种文字融入图片效果:
这个效果当时看到群里发出来的时候,我正在川西旅游,本想着回来之后试试写一下,结果回来之后发现网上已经有教程了:
后来又一直很忙,一直拖到现在快一个月了,还是写一下吧,算是个了结。
我这里总结了三种方法,前两种方法网上已经有很多教程了,最后一种方法是我自己研究的,不太好,也算是一种思路吧!
好了,废话不多说,让我们看看如何制作这种文字融入图片的效果吧!

01
前言及准备工作
虽说是三种方法,其实大体思路都差不多,都需要借助SD的Controlnet,只不过用到的模型不一样。
前两种方法文生图和图生图都可以,最后一种只能用图生图,我这里就统一用图生图来演示吧。
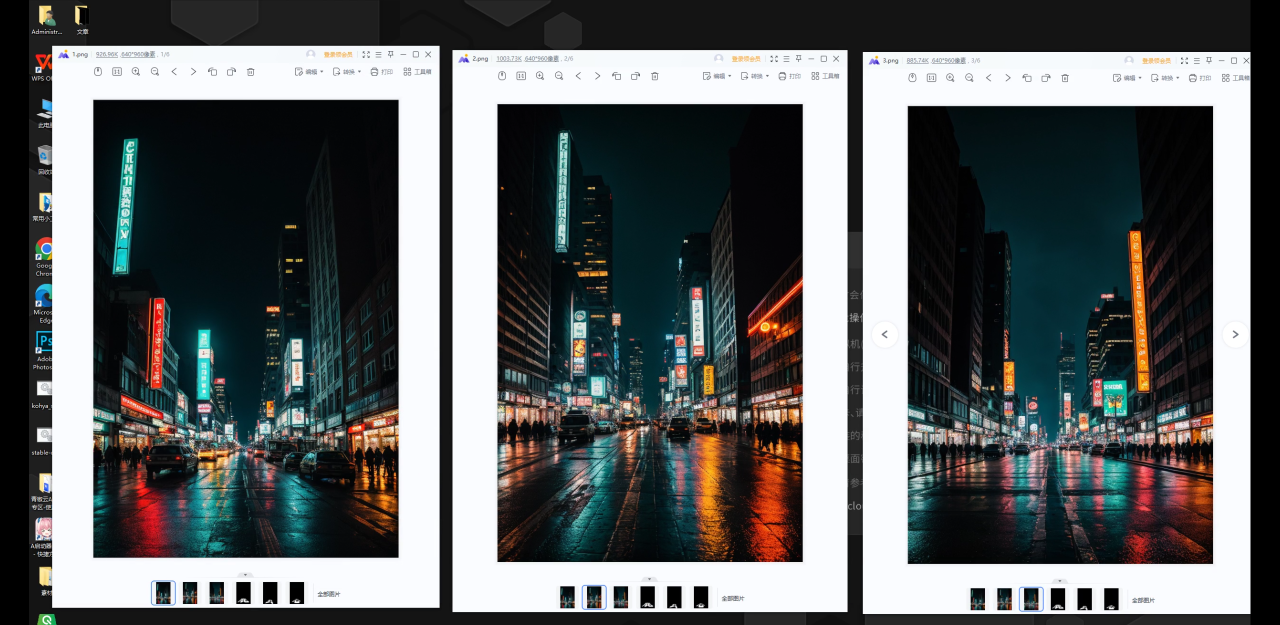
首先我用文生图生成了这样三张夜景图:
然后再用Ps制作了这样三张黑底白色的文字图,这里有两点提醒大家一下,首先文字可以适当高斯模糊一样,这样边缘不会太锐利。
其次文字的构图最好要参考一下你要融入的图片,特别是人物图,否则可能需要频抽卡才能得到比较满意的效果。
我这里是夜景图,就简单的把文字做了一下透视:
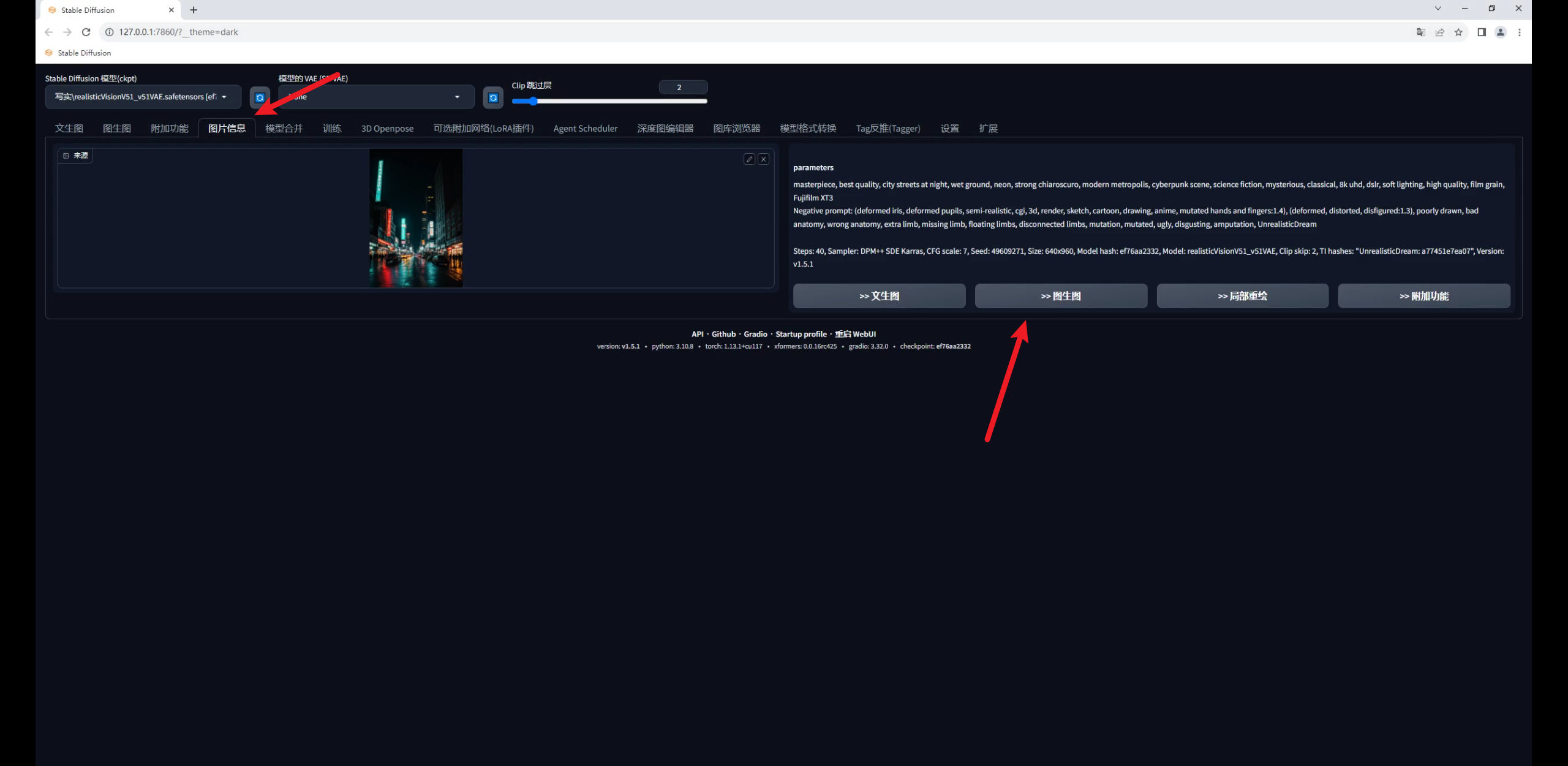
打开SD,在图片信息里载入夜景图获取它的提示词信息,然后直接发送到图生图:
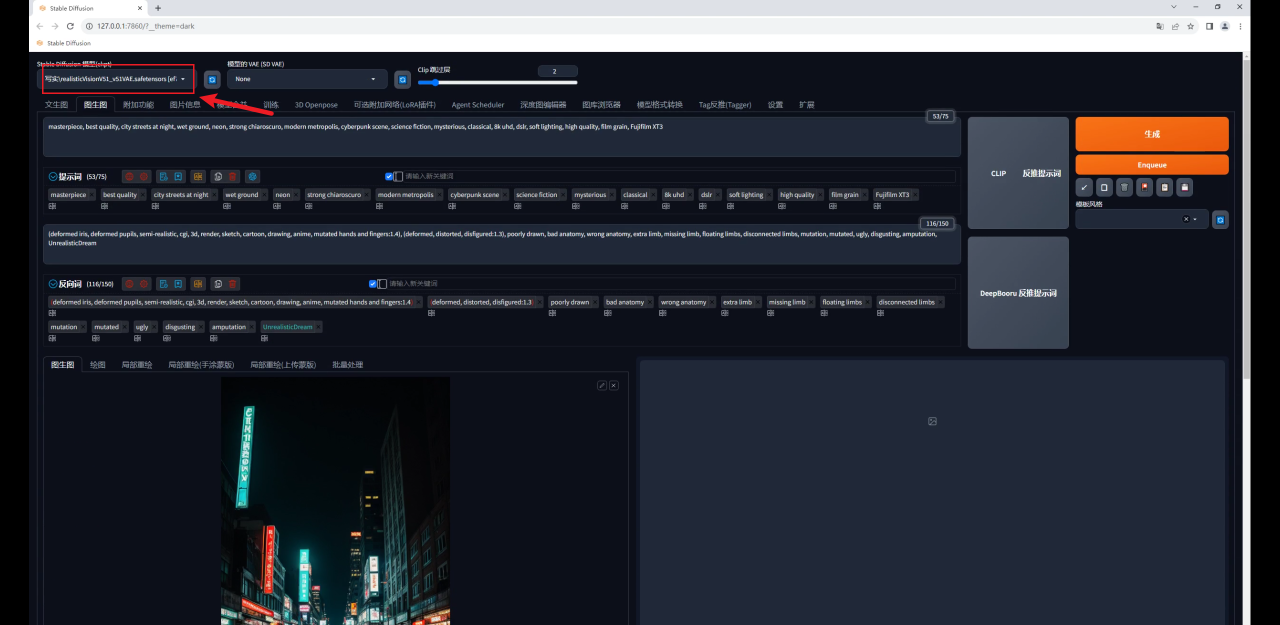
大模型我用的是Realistic Vision,这是C站下载量最高的一款写实类模型,也是我最常用的一款,目前已经更新到V5.1版本了:
做这种效果有一定的随机性,不要忘记保持随机种子为-1,方便抽卡:
02
使用Tile模型制作
第一种方式是使用Controlnet Tile模型制作,这个是Controlnet 1.1新增的一个模型。
模型以及预处理器在上一篇Controlnet通用参数的文章中已经分享给大家了,各位鹿友可以自行去获取:

这个模型最大的特点是它会根据你在Controlnet中输入的图片信息在原图中绘制新的细节。
因此它通常用于放大图像,后面的文章我也会给大家分享我在工作中常用的两种批量放大图片的方法:
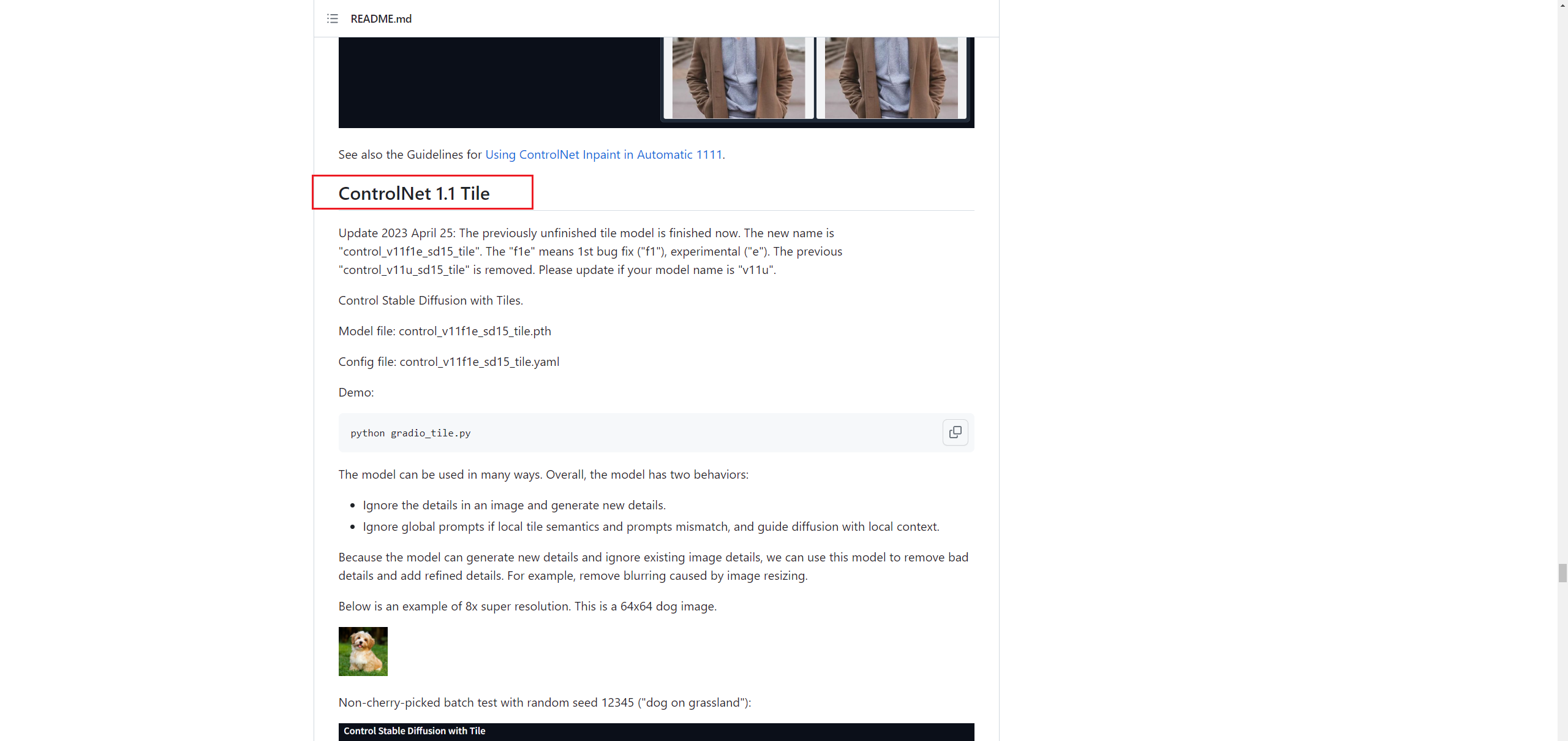
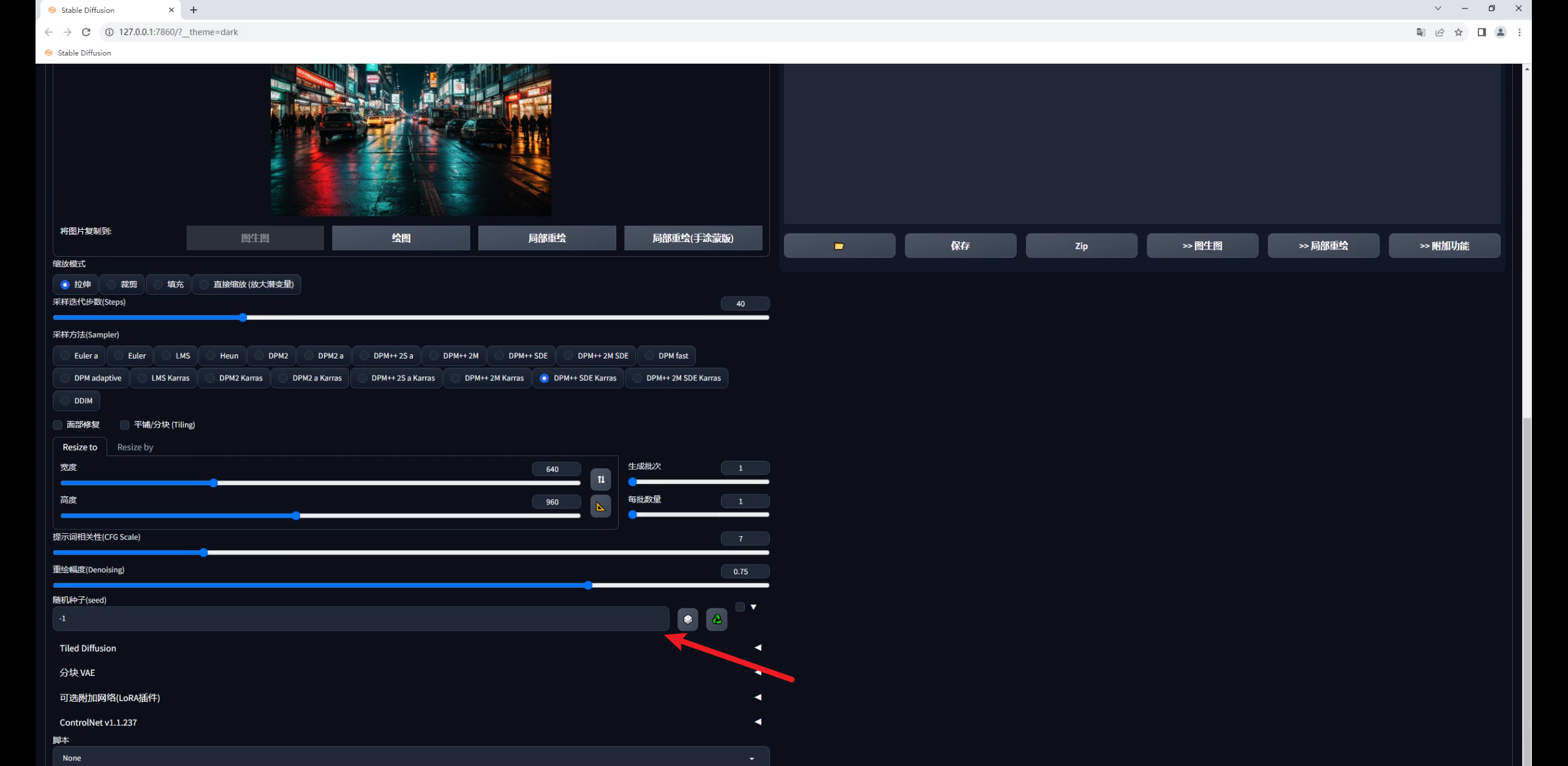
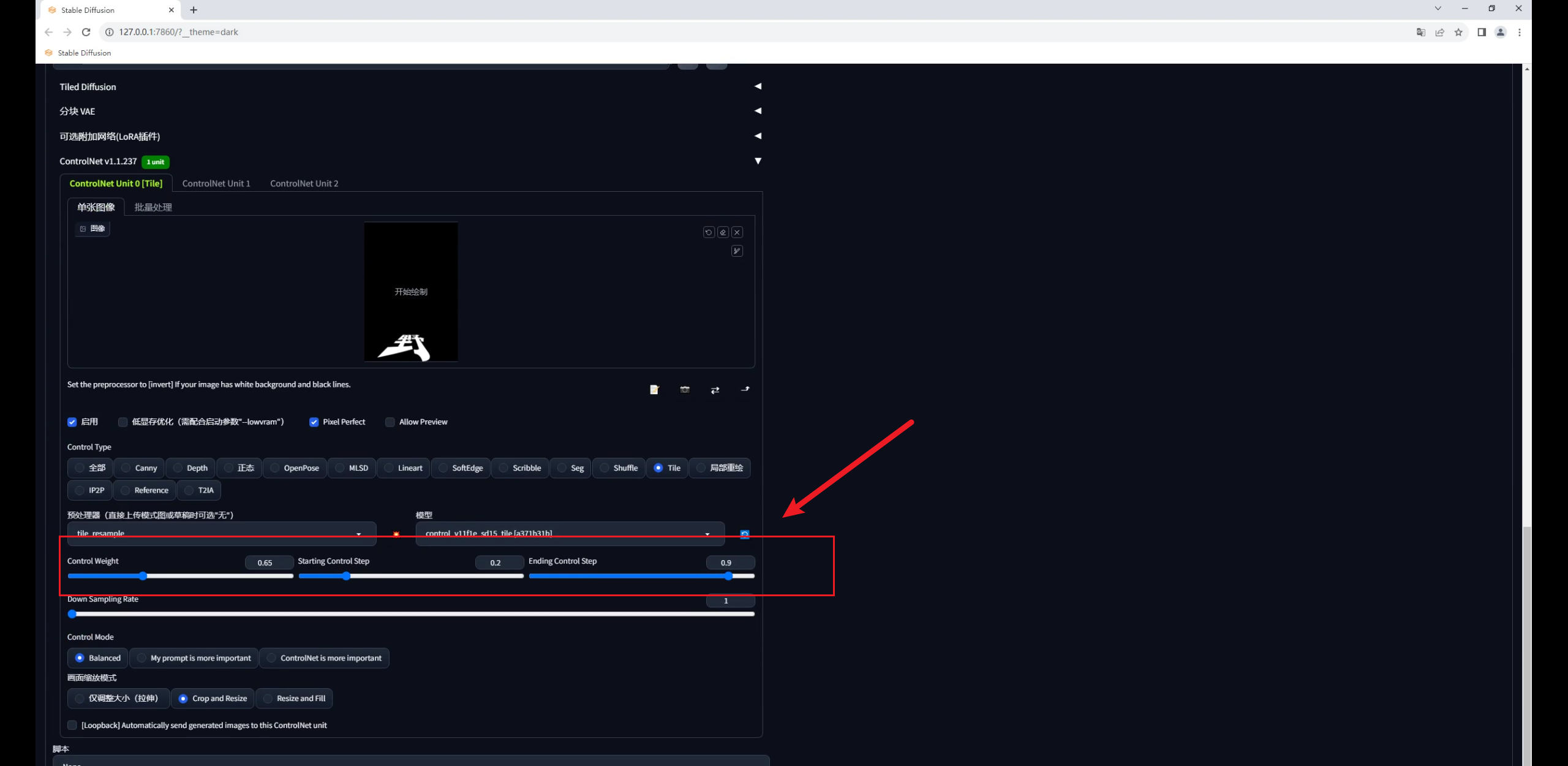
回到SD中,先把文字图拖进Controlnet里,勾选启用和完美像素:
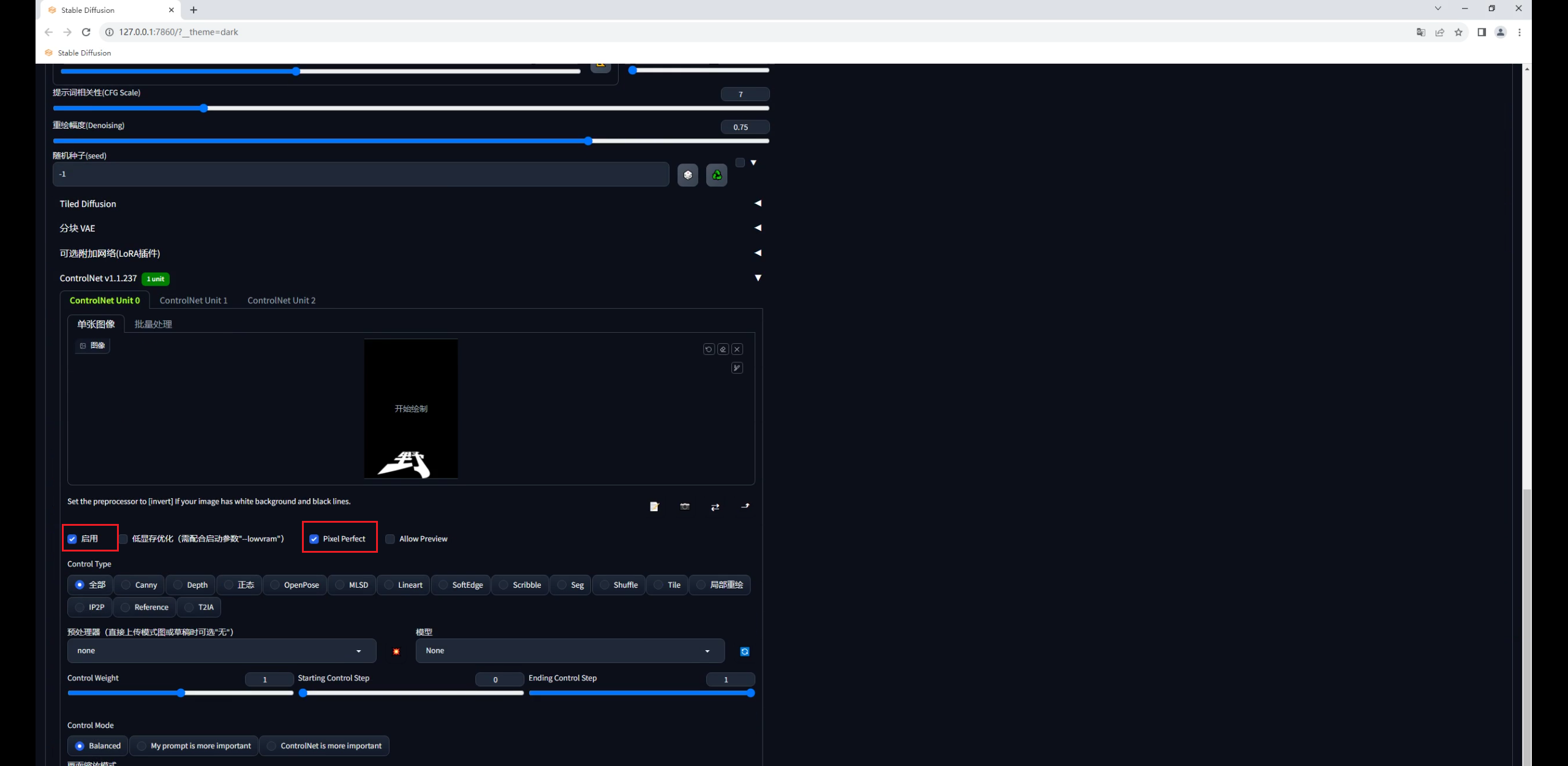
控制类型选择Tile,这个模型有三种预处理,分别是颜色覆盖、颜色覆盖加锐化,重采样。
前面两种我测试过,由于我们输入的文字图是黑底的,使用颜色覆盖生成的图像会很暗。
因此我们就选择重采样这种方式就好,爆炸图标点不点都没关系:
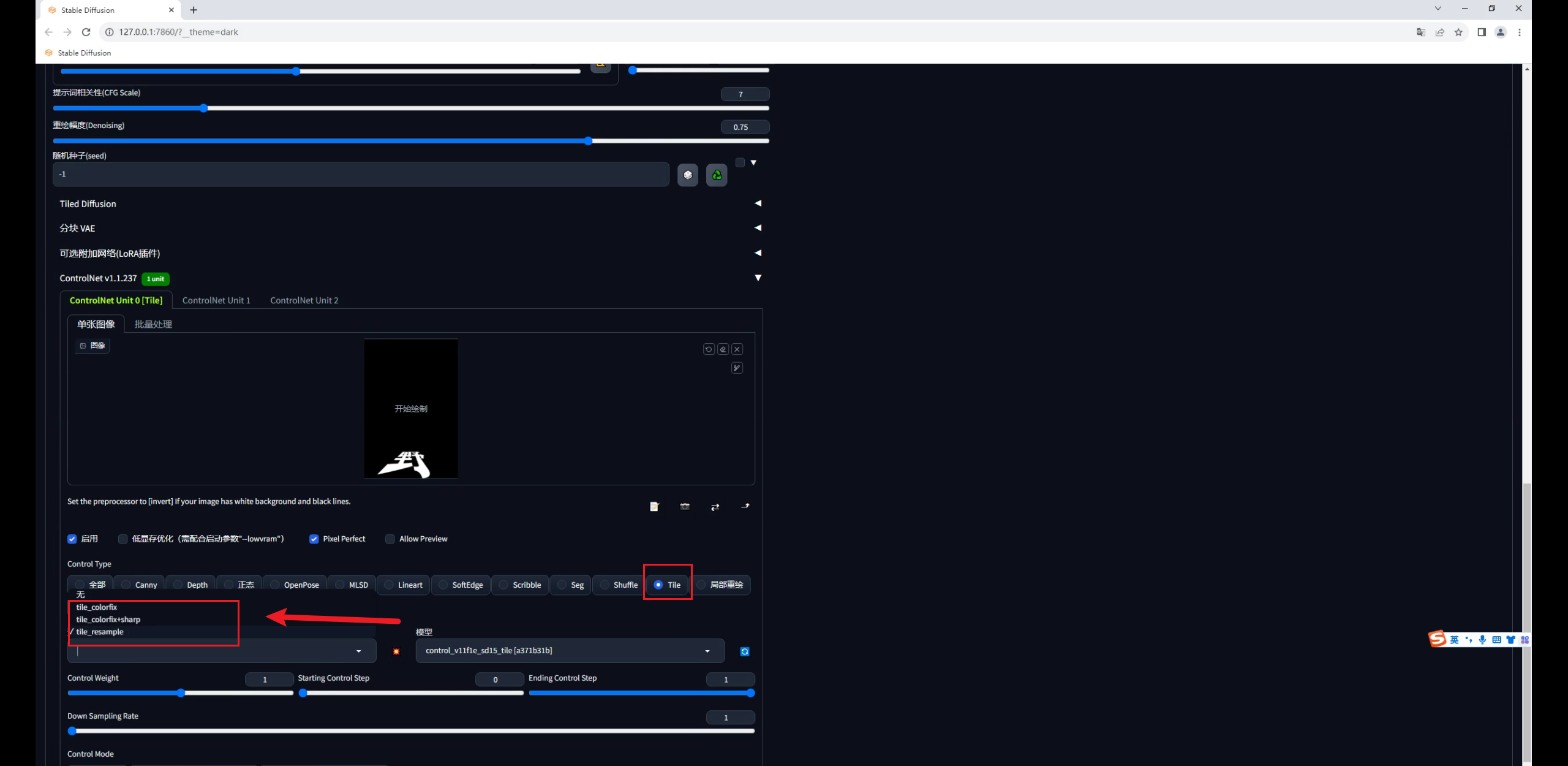
先直接生成一张图看看,你会发现文字过于清楚,画面变黑了:
这是因为Tile的影响太大了,我们可以适当的调整权重以及开始和结束控制的介入步数。
这三个参数的数值不是固定的,和你的原图有关,大家实际操作中可以自行测试:
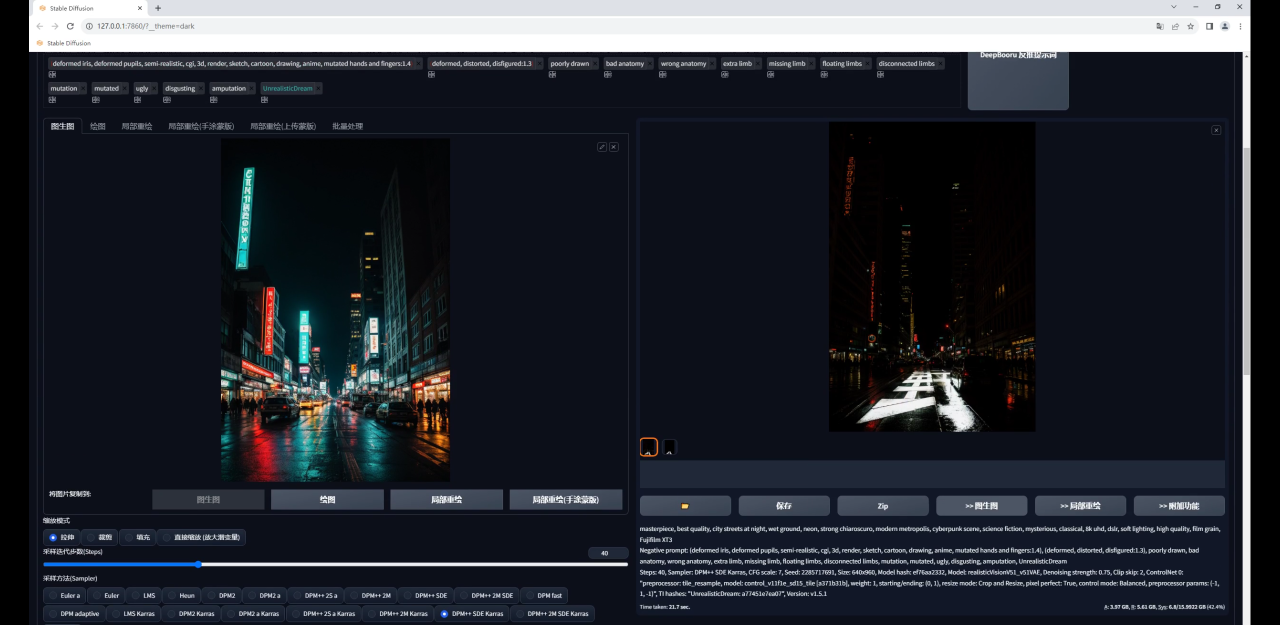
当我们适当调整参数以后,效果就好多了:
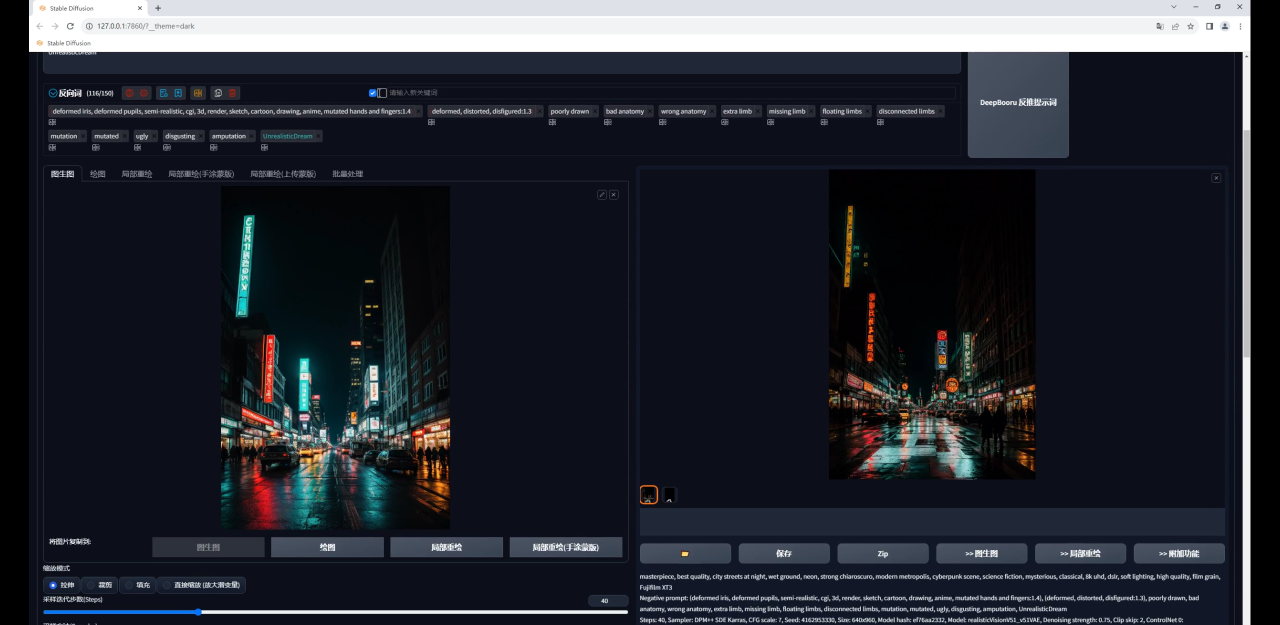
不过你可能会发现生成的图和原图差别比较大,这是由于我们图生图的重绘幅度过高导致的:
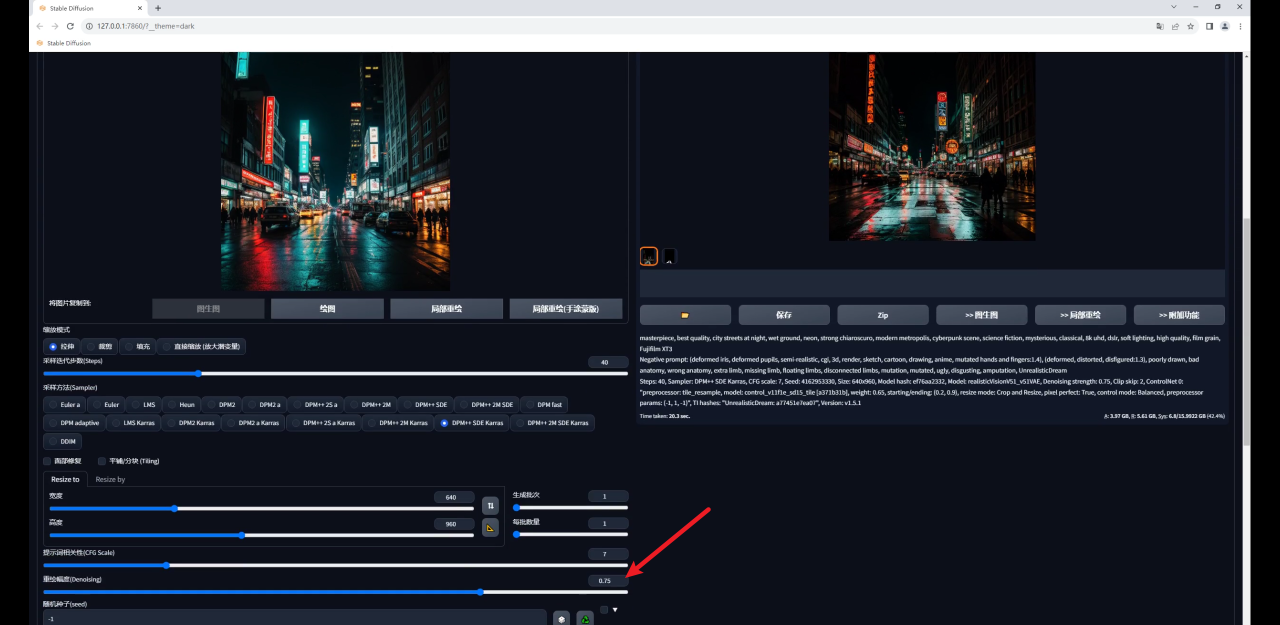
如果你希望生成的图像尽量和原图相似,可以适当的降低重绘幅度:
但需要注意的是降低重绘幅度也会降低Tile对生成图的影响,我们前面也提到了,Tile会绘制新的细节,重绘幅度降低了当然影响就弱了。
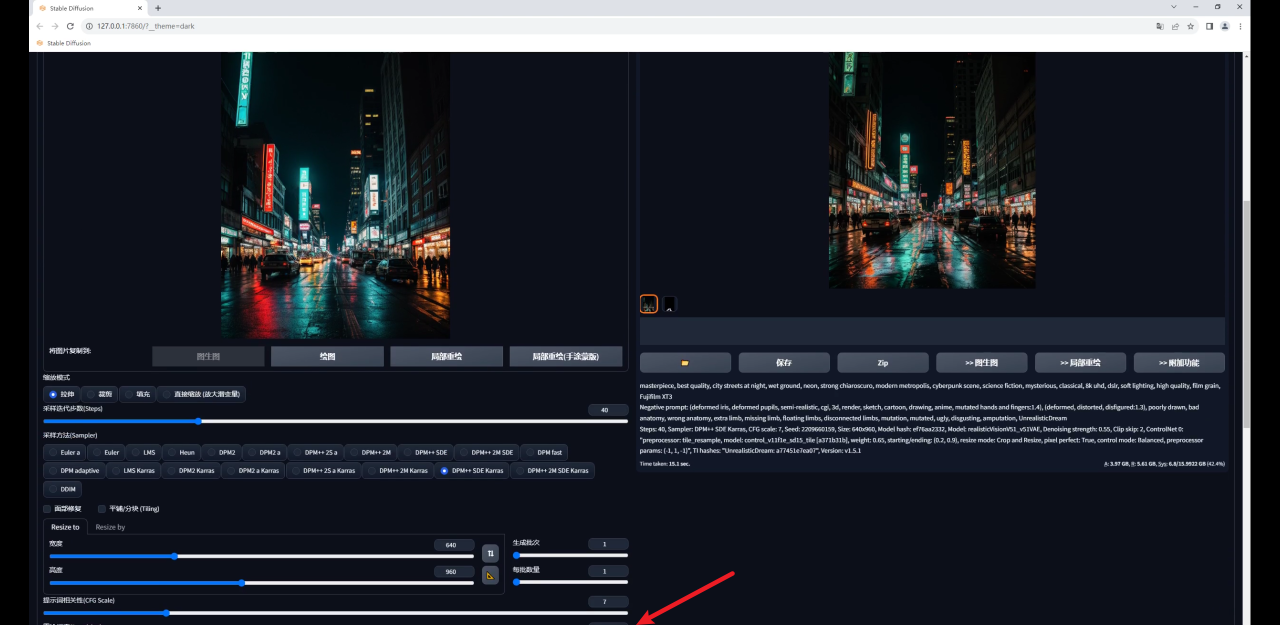
因此如果希望生成图和原图保持一致,就需要低重绘幅度高权重,反之同理,我这里将权重提高到了0.8,感觉是我想要的效果:
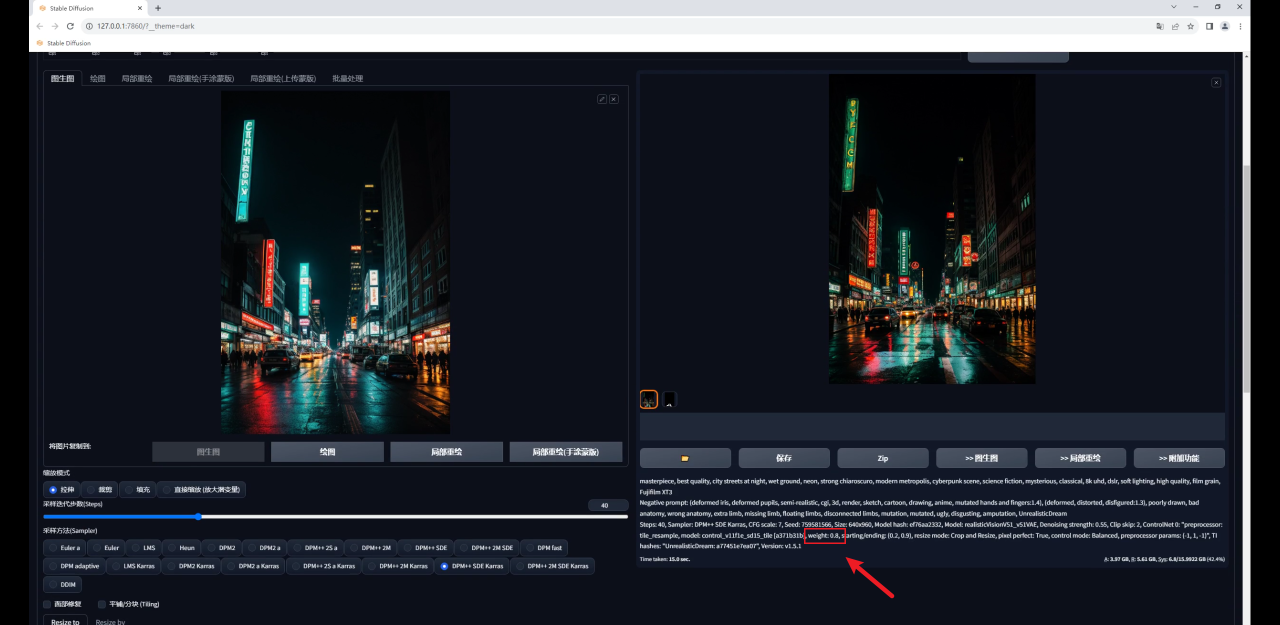
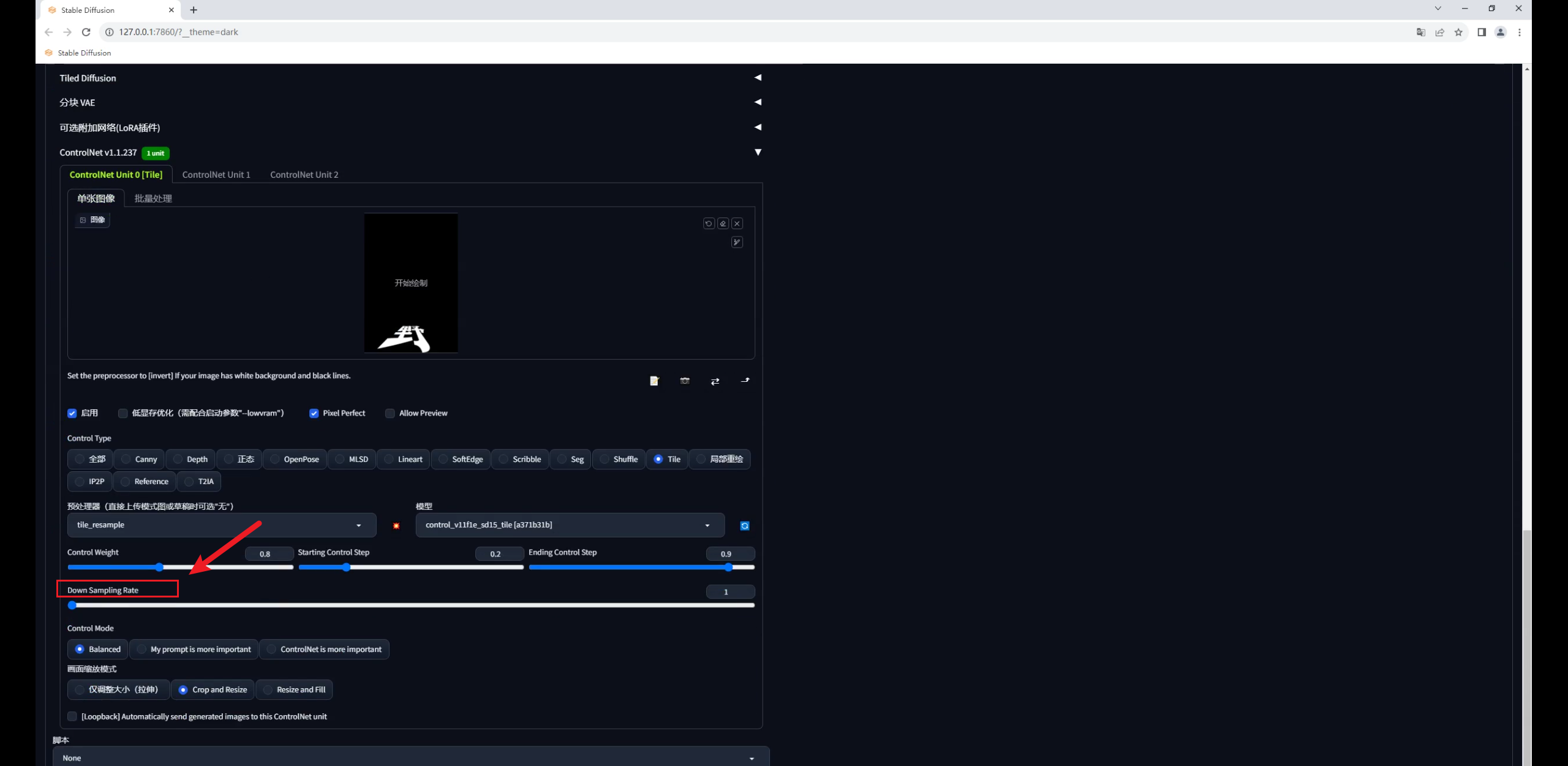
Tile还有一个降低采样率的参数,这个数值越高,重绘的细节越少:
最后放大图看看效果吧:

03
使用第三方模型制作
第二种方法是使用两种第三方训练的Controlnet模型。
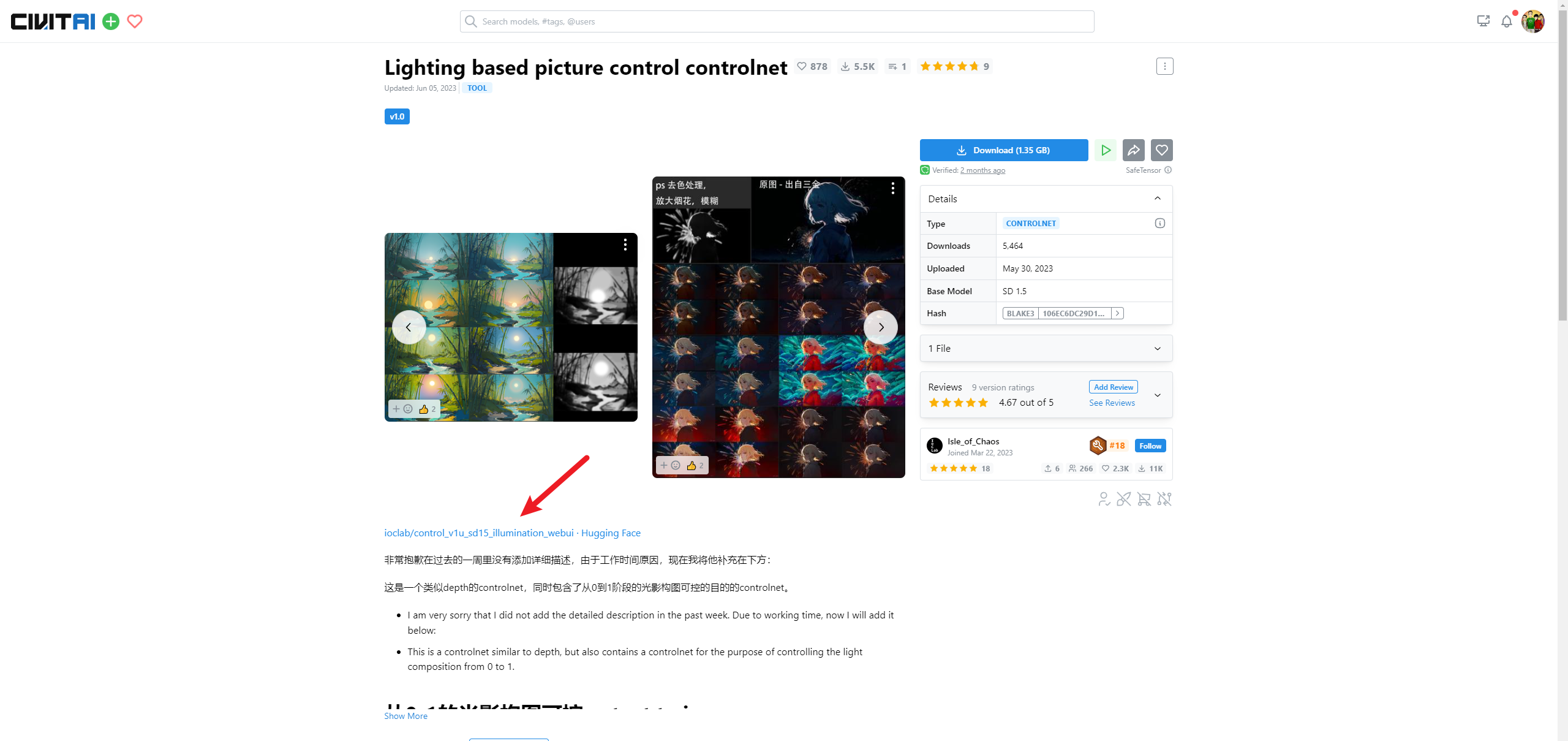
第一款在C站上的名字叫Lighting based picture control controlnet,在抱脸网上的名字叫illumination:
第二款在C站的名字叫Brightness:
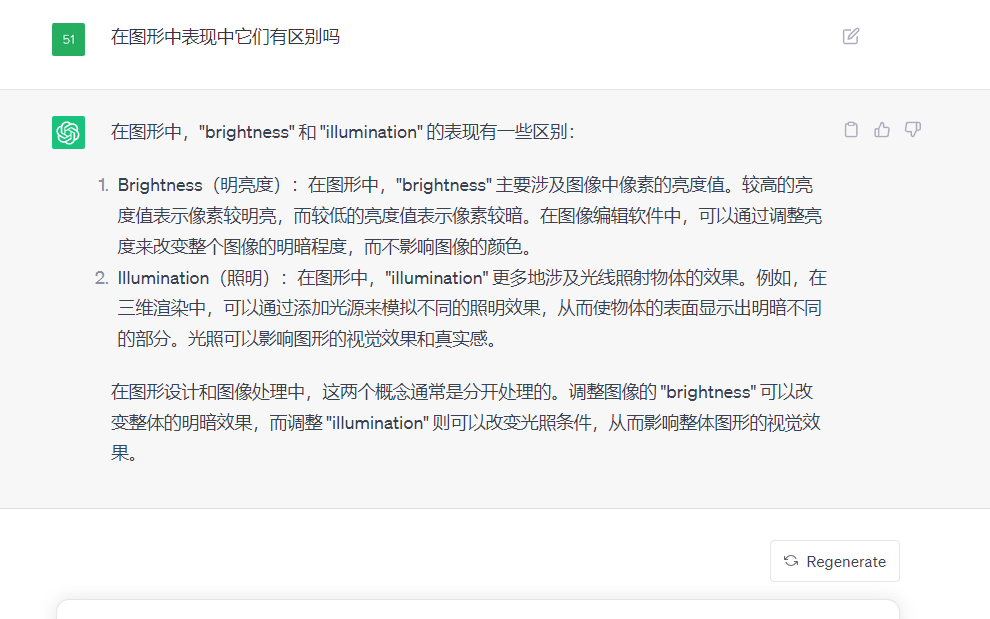
这两个名字很相似,Illumination是照明,Brightness是明亮度,两个模型可以单独使用。
相比于Tile模型,这两款模型更偏向于制作光影的效果,下面是chatgpt对它们的区别解释:
这两款模型可能是同一个团队训练的,文后我也会把这两款模型分享给大家:
使用的思路方面是Tile模型是一样的,首先是Lighting based picture这个模型。
载入文字图片,预处理器这里选择无,模型选择Lighting based picture:
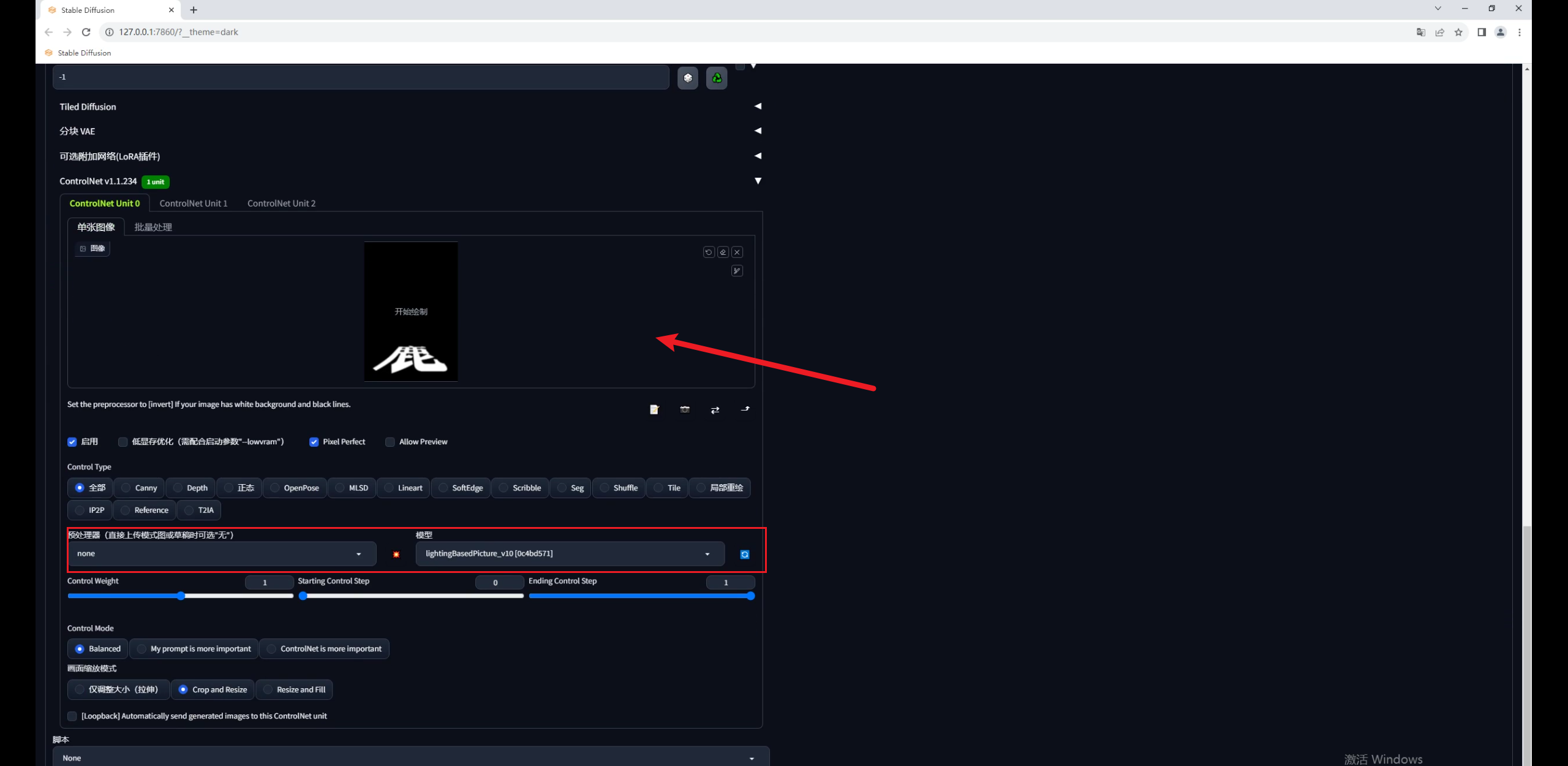
注意,我现在的重绘幅度是默认的0.75,直接点击生成看一下,同样画面变得很暗,文字过于清晰:
因此同样调整参数,权重0.35,开始和结束控制的介入步数分别是0.2和0.9,效果就好多了:
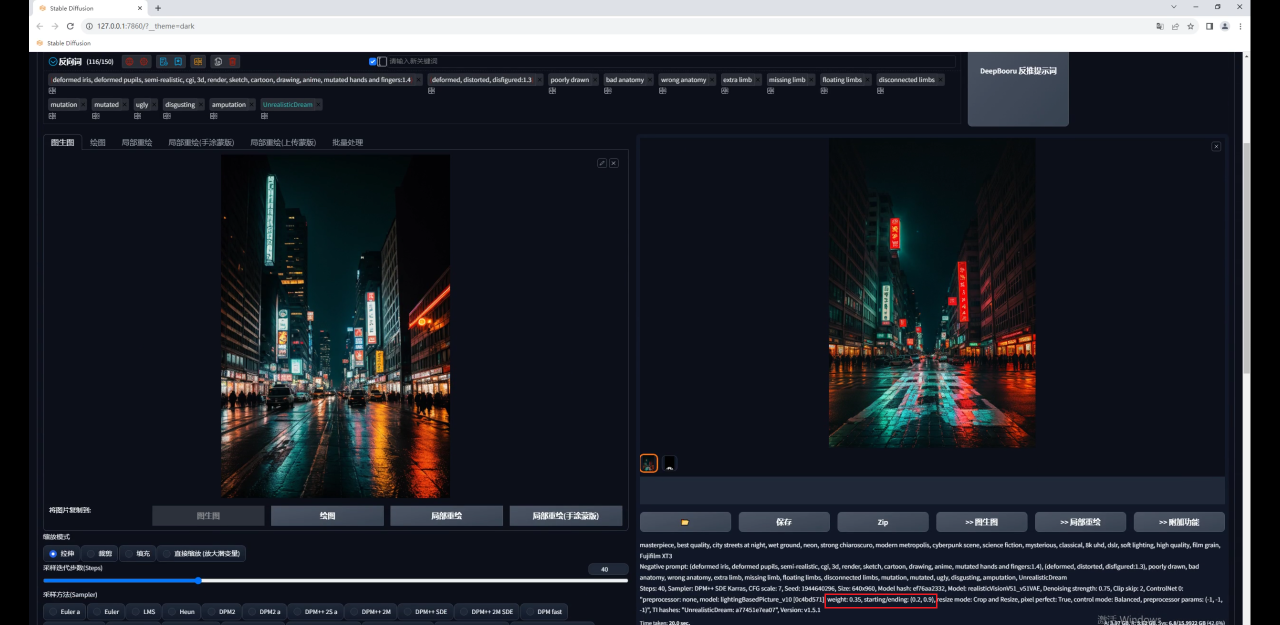
同样的如果你希望画面尽量保持不变,就需要降低重绘幅度,然后提高Controlnet的权重:
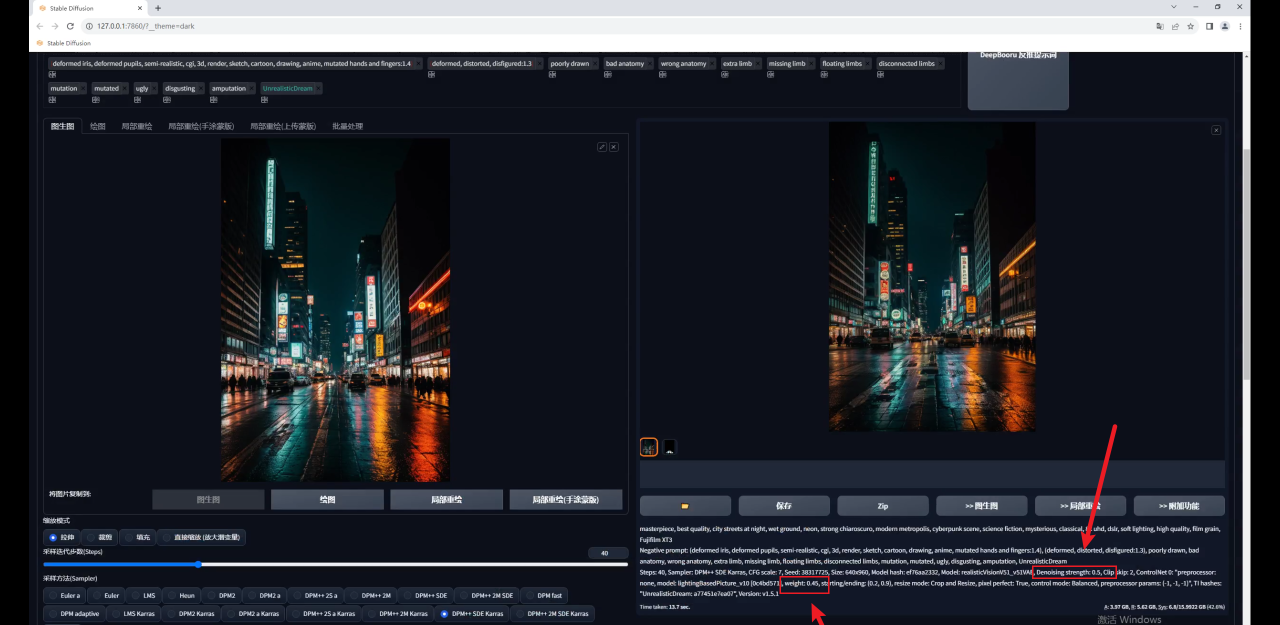
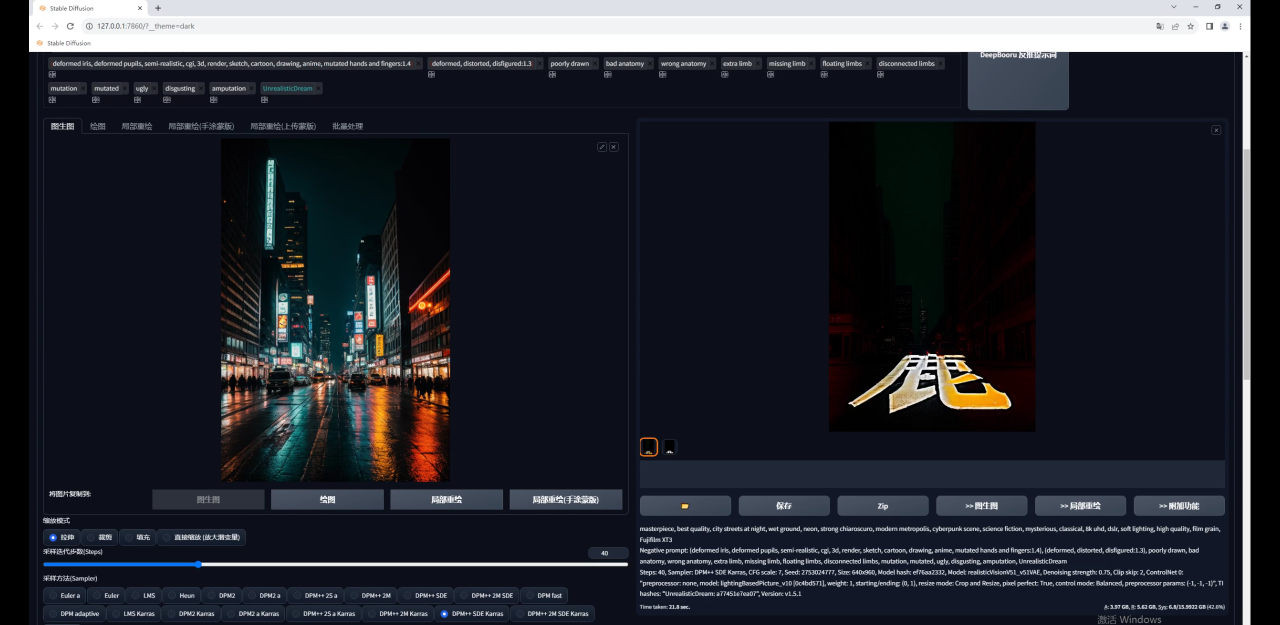
放大图片看看效果吧:

至于Brightness模型也是一样,无非就是测试这三个关键参数,预处理器选择无就行:
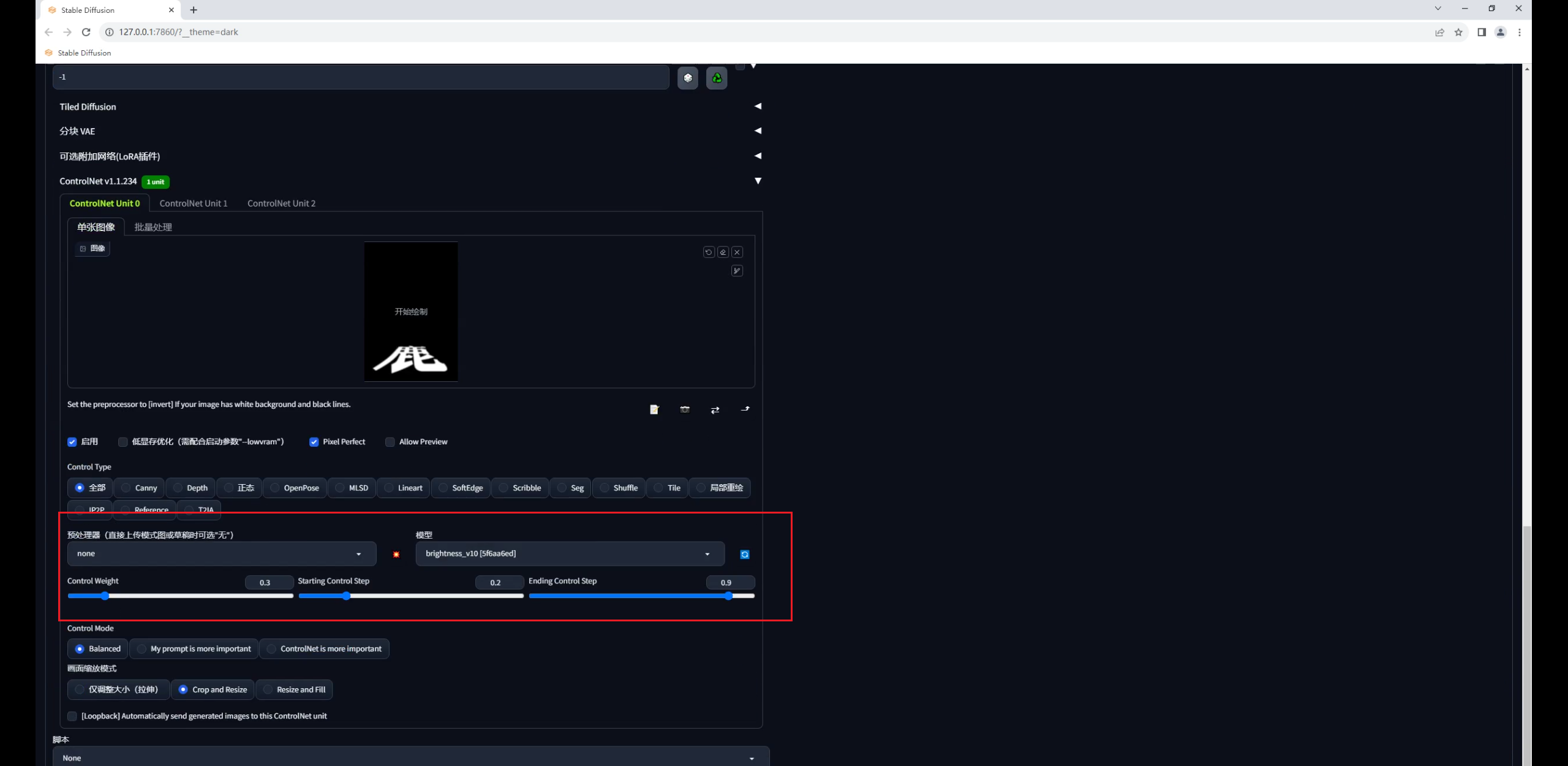
这个是Brightness放大后的效果:

04
使用Depth+轮廓类模型制作
这是我自己研究的方法,只能用于图生图,并且可控性不高,随机性很大,大家仅做了解吧!
首先通过图片信息功能,在提示词栏位输入和生成图相同的题词:
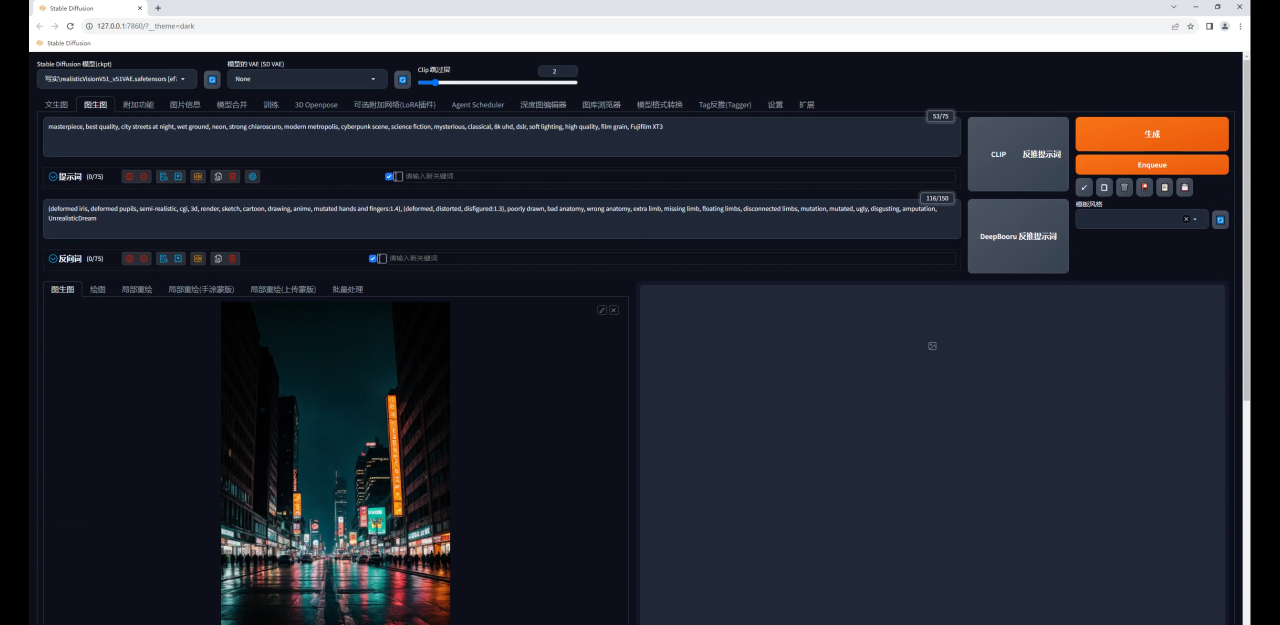
在文生图输入栏位把原图替换为文字图:
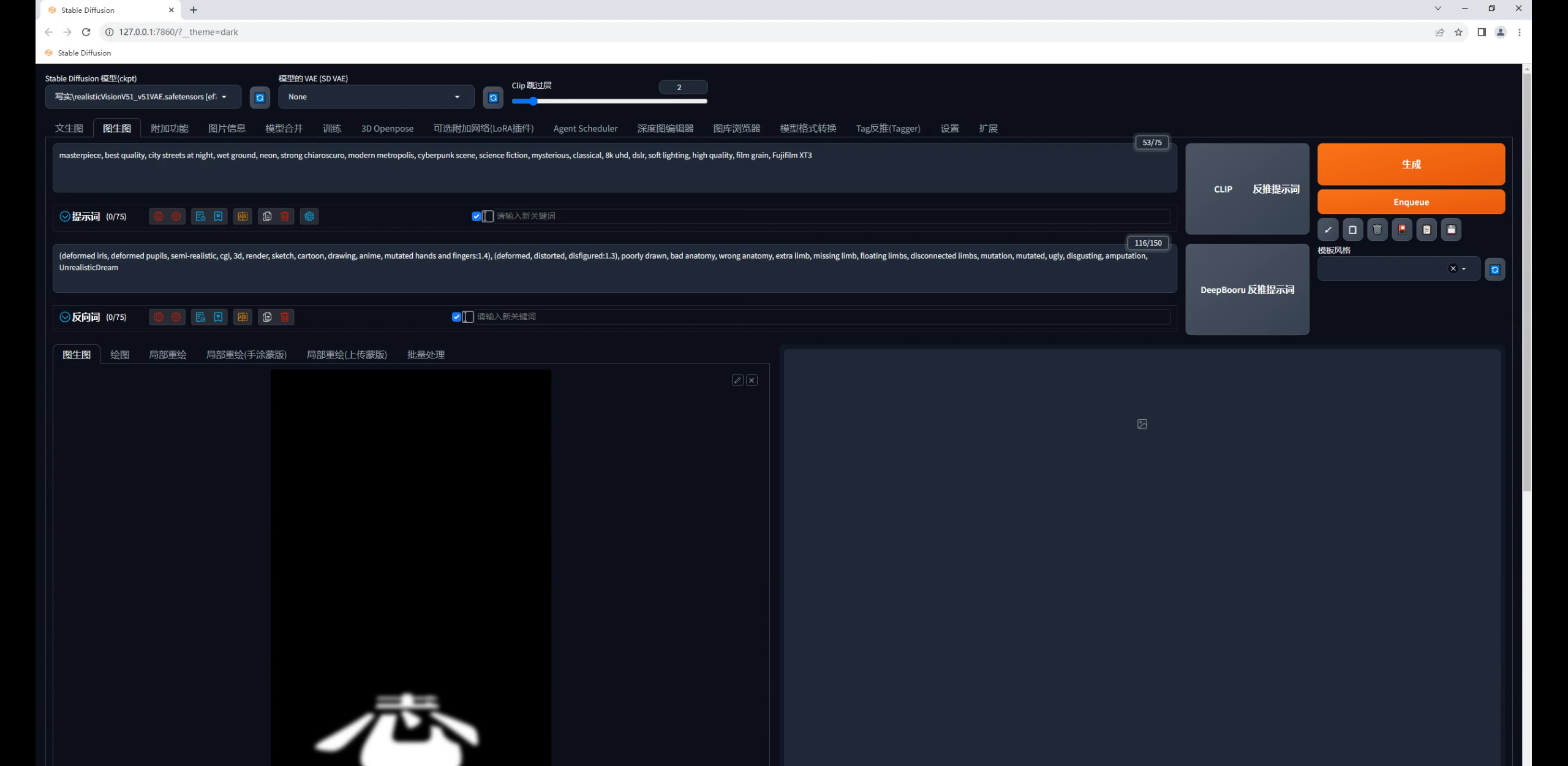
再在Controlnet中载入夜景图,模型选择深度图,预处理器用最精准的depth leres++,爆炸一下:
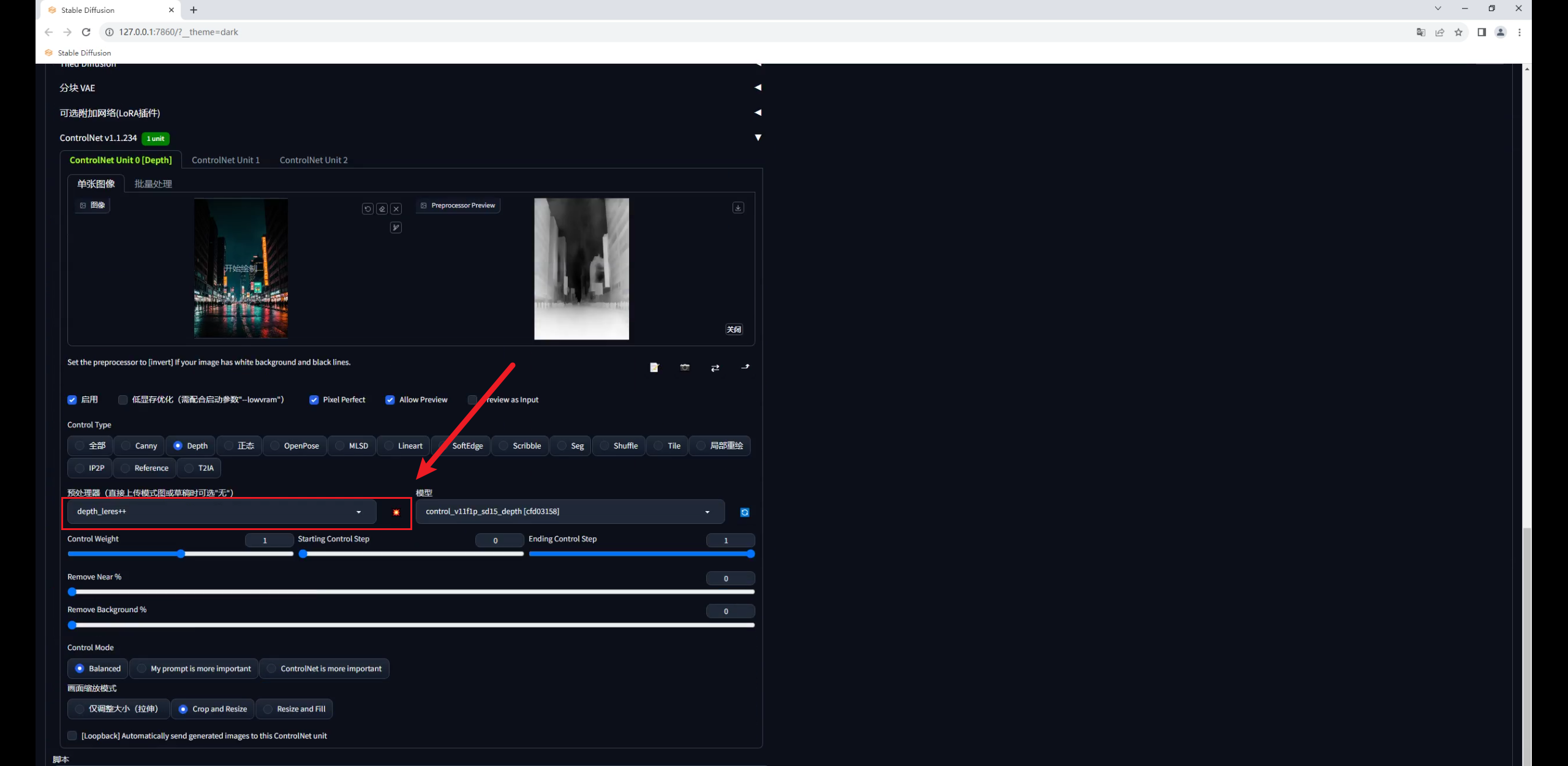
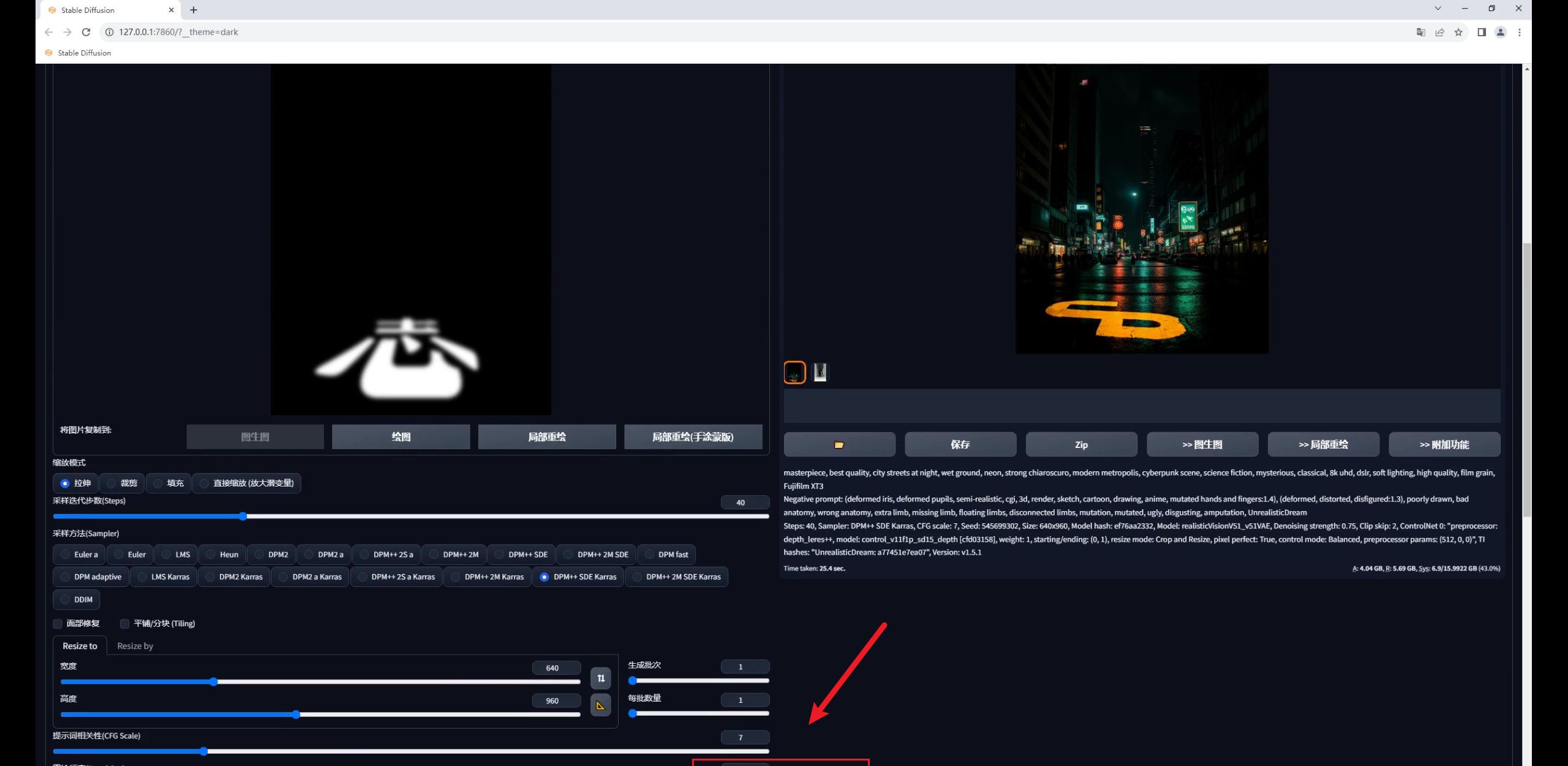
默认重绘幅度0.75,点击生成你会发现图片变暗了,文字识别也不太准确。
图片变暗是由于图生图识别的是输入图的颜色信息,图片大部分是黑色,所以会变暗。
而文字识别不太准确是因为虽然图生图能读取颜色信息,但0.75的重绘幅度足以让生成图与原图产生较大的差异,并且设置中没有能固定文字的设置:
因此我们需要再加入一个能固定文字形态的控制,比如在第二个Controlnet中加入一个SoftEdge软化边缘的模型,预处理器我这里选择的是SoftEdge hed:
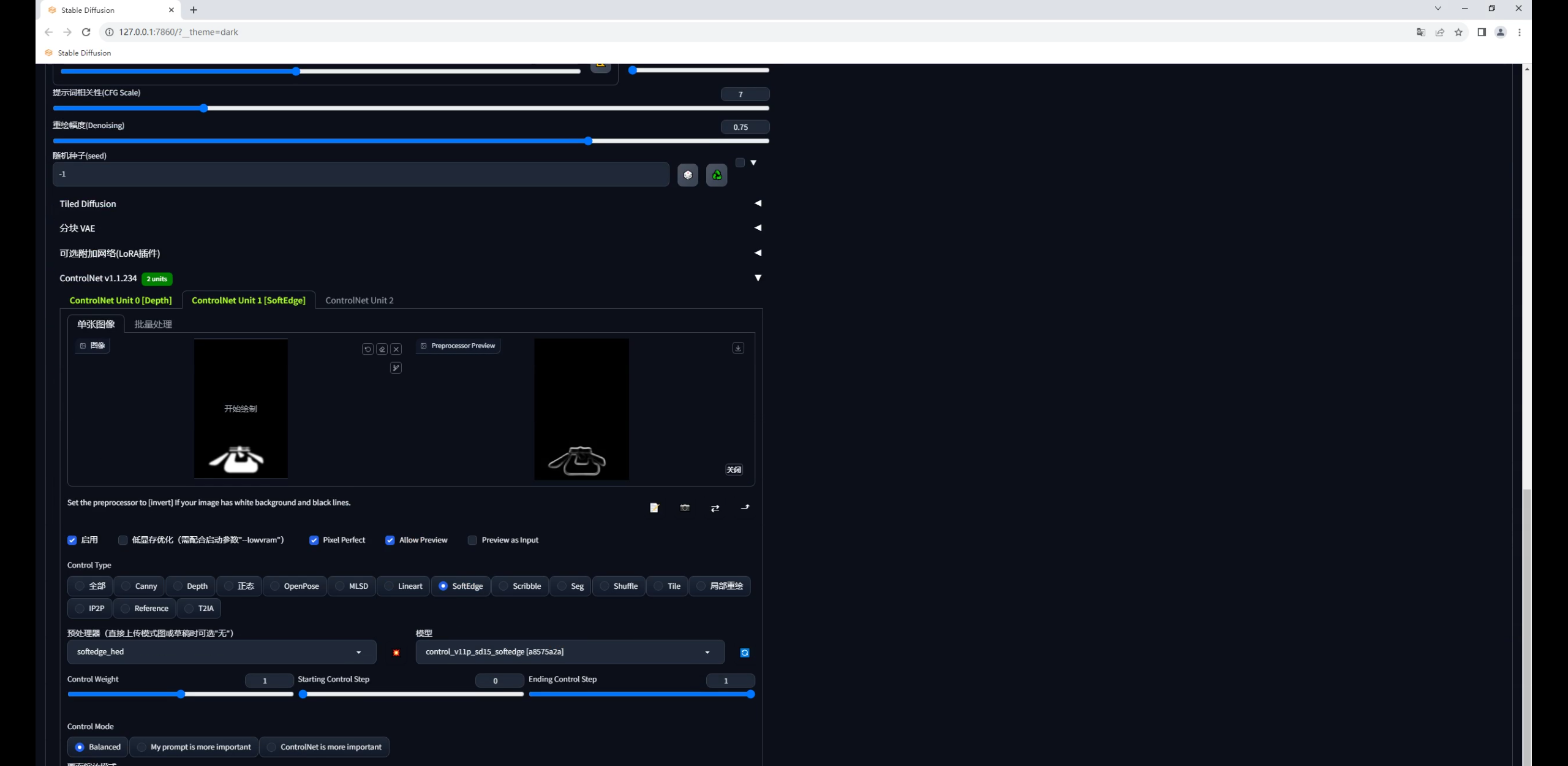
权重可以适当降低一点,然后就开始抽卡,你会发现图片很暗并且文字过于清晰。
这是是由于重绘幅度还不够导致的,因为这次我们是直接在图生图中输入的是文字图:
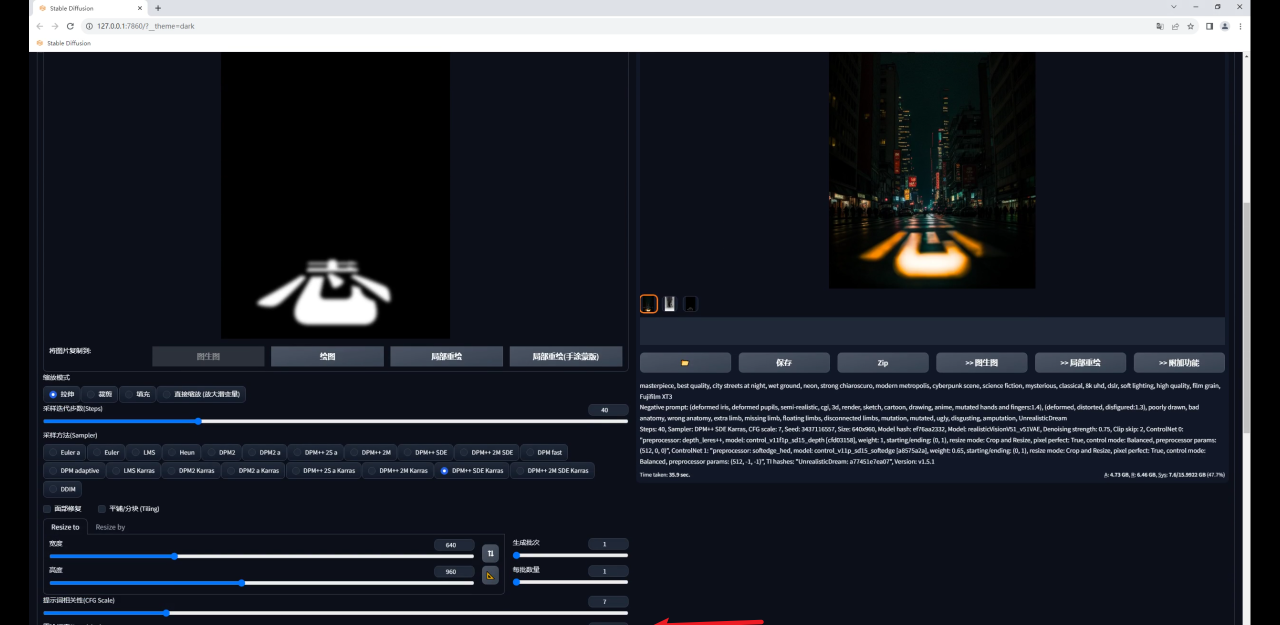
这种方法的思路是在Controlnet1.1之前,几乎没有模型能够识别图片的颜色信息。
因此我们可以借助图生图识别图片颜色信息的功能告诉SD什么地方是亮的,同时用Depth模型控制深度关系,最后再用轮廓类的模型来进一步限制文字的外形。
我们可以再次提高重绘幅度,然后抽卡得到一个感觉还不错的效果:
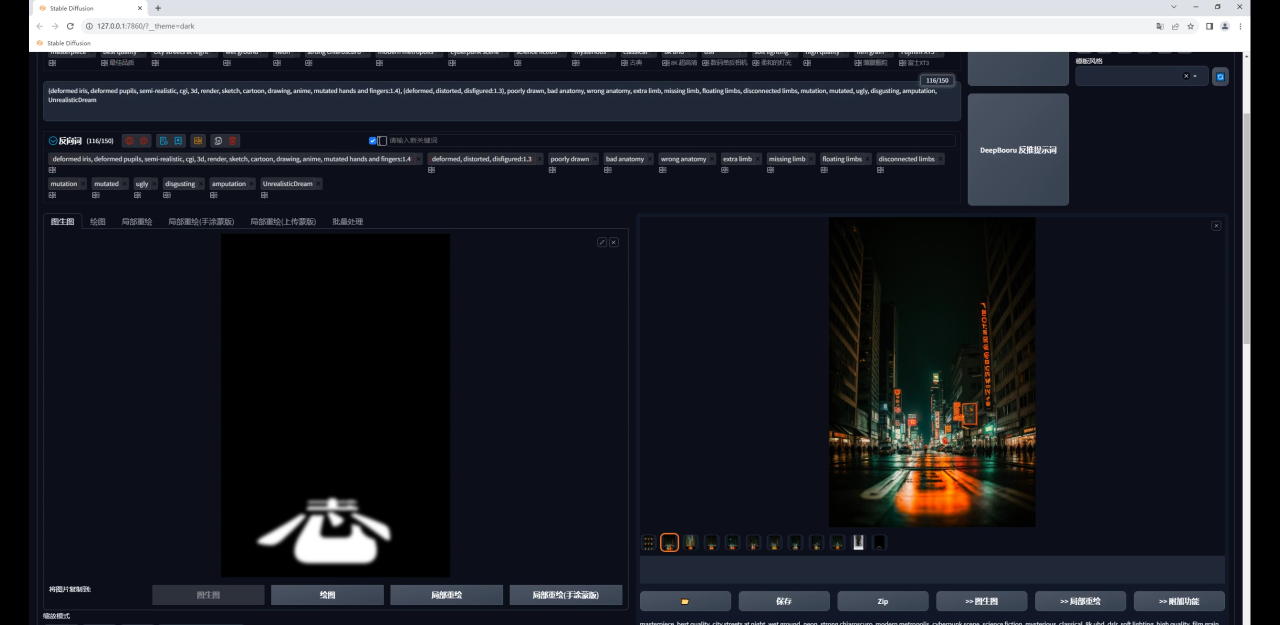
不过这种方法最大的问题是可控性比较差,你可能需要多次抽卡才能得到一张比较满意的图,并且由于重绘幅度高,所以生成图与原图的差异也比较大。
最后图片放大看看效果吧:

以上就是今天想要分享的所有内容。
如果觉得对自己有所帮助,请不要吝啬自己的一键三连,你们的支持对我很重要,谢谢!
更多内容欢迎关注公众号:
本文由“野鹿志”发布
转载前请联系马鹿野郎




热门课程推荐

热门资讯
-
1. 华为手机神奇“AI修图”功能,一键消除衣服!原图变身大V领深V!
最近华为手机Pura70推出的“AI修图”功能引发热议,通过简单操作可以让照片中的人物换装。想了解更多这款神奇功能的使用方法吗?点击查看!
-
近年来,人工智能逐渐走入公众视野,其中的AI图像生成技术尤为引人注目。只需在特定软件中输入关键词描述语以及上传参考图就能智能高效生成符合要求的...
-
想将照片变成漫画效果?这篇文章分享了4个方法,包括Photoshop、聪明灵犀、VanceAI Toongineer、醒图,简单操作就能实现,快来尝试一下吧!
-
4. 一款免费无限制的AI视频生成工具火了!国内无障碍访问!附教程
人人都可以动手制作AI视频! 打开网址https://pixverse.ai/,用邮箱注册后,点击右上角Create,就可以开始创作了。 PixVerse目前有文案生成视频,和图片生...
-
以下是一些免费的AI视频制作网站或工具,帮助您制作各种类型的视频。 1. Lumen5:Lumen5是一个基于AI的视频制作工具,可将文本转换为视频。 用户可以使...
-
6. 零基础10分钟生成漫画,教大家如何用AI生成自己的漫画
接下来,我将亲自引导你,使用AI工具,创作一本既有趣又能带来盈利的漫画。我们将一起探索如何利用这个工具,发挥你的创意,制作出令人惊叹的漫画作品。让...
-
就能快速生成一幅极具艺术效果的作品,让现实中不懂绘画的人也能参与其中创作!真的超赞哒~趣趣分享几款超厉害的AI绘画软件,提供详细操作!有需要的快来...
-
8. AI视频制作神器Viggle:让静态人物动起来,创意无限!
Viggle AI是一款免费制作视频的AI工具,能让静态人物图片动起来,快来了解Viggle AI的功能和优势吧!
-
9. 10个建筑AI工具,从设计到施工全覆盖!肯定有你从来没听过的
讲述了建筑业比较著名的AI公司小库科技做出的探索,在这儿就不多说了。今天,我们试着在规划设计、建筑方案设计、住宅设计、管道设计、出渲染图、3D扫...
-
10. Logo Diffusion——基于sd绘画模型的AI LOGO 生成器
这下LOGO设计彻底不用求人了。接下来详细演示一遍操作流程首先进入Logo D... 想学习更多AI技能,比如说关于怎么样利用AI来提高生产效率、还能做什么AI...
最新文章
