 火星网校
火星网校
字节火山引擎Seedance25全面评测30s视频一次性直出4K画质音画同步太牛了
 作者:脑洞君
发布时间: 2026-06-30 17:23:30
浏览量:0次
作者:脑洞君
发布时间: 2026-06-30 17:23:30
浏览量:0次
6月23日,字节跳动在火山引擎FORCE大会上正式发布了Seedance 2.5。这是他们全新一代的视频生成模型,一段可直出时长30秒、原生4K、音画同步的AI视频,而且是单次推理直出,不拼接、不补帧。

这对AI短剧、漫剧创作者,和正在学习AI创作的同学们来说,意味着什么?
30秒,改变了什么
此前大多数AI视频工具,单次生成上限在8-15秒左右。想要更长的镜头,就得分段生成再手动拼接——每个接缝处,都是人物走样、光线突变、动作错位的高危地带
Seedance 2.5把这个上限推到了单段原生30秒。
这不只是数字的提升。它意味着:
一个角色走进房间、坐下、开口说话这种复杂的长镜头,可以一次完整生成;
运镜从远景拉到近景的完整过程,不需要手工拼接;
甚至产品广告的"揭晓-展示-特写"三段式,也可以用一条提示词搞定
这对做AI漫剧甚至AI广告的创作者来说,这直接减少了至少一半的后期对帧工作量!
50个参考,角色一致性概率大幅提升
做过AI短剧的人都知道最头疼的问题是什么:
角色一换镜头,就不是同一个人了。
Seedance 2.5现在可以单次生成最多支持50个全模态参考输入(上一代Seedance 2.0的上限是12个)
50个意味着什么?你可以直接一次性把角色参考图(主角正面、侧面、不同表情)、服装参考(反面、细节图、多场景)、风格参考(运镜语言、色调、光效)和音频参考(声线、语速、情绪基调)等等,一次喂进去。
而且这50个参考,不是简单的要素叠加,而是在同一次推理里协同约束,让模型"记住"你要的这个人。
这对连载型AI漫剧尤其关键:主角跨集保持形象一致,是商业变现的基本门槛,现在有了更可靠的技术支撑。

音画同步,终于不用单独配音了
过去的工作流:生成视频→用Wav2Lip做口型同步→再叠加音效和配乐。
Seedance 2.5把这个流程压缩了:音频和视频在同一次推理中联合生成。
你可以在提示词里描述声音:"角色低沉的嗓音,雨天室内的空调白噪音,玻璃窗上雨滴滑落的声音",这样生成出来的视频,声音天然嵌在画面里,不是后期叠上去的。
脚步声踩在地板上的那一帧,音效就在那一帧。这是当前多数工具做不到的。
3D白模预可视化:先看布局,再出成片
这是一个对商业化内容创作者来说相当实用的新功能。
你可以先提交3D白模(Blockout),看清楚场景空间关系、角色站位、镜头取景等等,在正式渲染前确认一遍布局是否符合预期。
不符合预期,直接改,等确认无问题了,再跑完整渲染。
这对广告视频、系列漫剧的分镜设计非常友好:不用等渲染完才发现角色站错了位置,省时省钱。
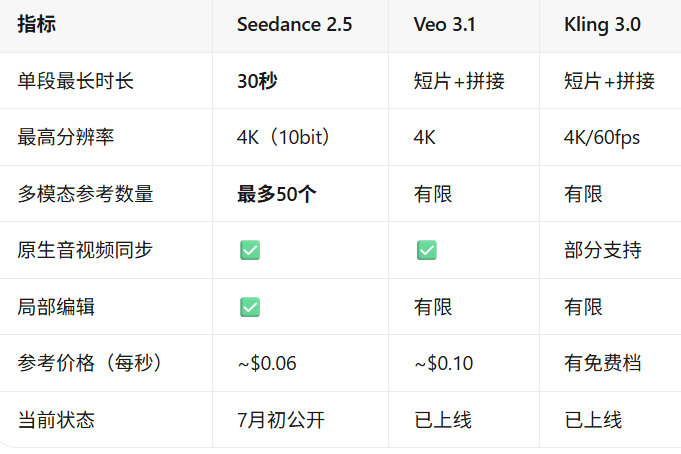
可以再看下Seedance 2.5和同期其他同类产品的横向对比:
Seedance 2.5的局限性
全面评测,不能只说好话。
Seedance 2.5目前仍在企业测试阶段,7月初才公开上线,以下问题来自行业测试者的反馈:
对AI漫剧创作者的具体建议
你现在能做的:
真正值得期待的场景:
系列漫剧的"主角形象锁定"问题,一直是AI短剧品控的核心痛点。Seedance 2.5的50参考机制,是目前技术路径里最接近解决方案的一个答案。
配合3D预可视化做分镜,理论上可以大幅降低"拍完才发现整集视觉不统一"的返工率。
写在最后
Seedance 2.5是目前可查到的、单段生成时长最长、参考控制能力最强的AI视频模型。字节跳动把它整合进了豆包/即梦/剪映的完整生态,意味着国内的AI内容创作者将是最先吃到红利的群体。
Seedance 2.5将于7月初公开上线,让我们拭目以待
还想看什么?可以在评论区留下你的?,我会继续为大家整理AI前沿资讯~
火星时代将第一时间把Seedance 2.5应用在课程教学当中,你可以直接点击文末左下角“阅读原文”咨询AIGC课程~!
相关阅读



如果觉得有用,随手点个赞、在看、转发。也可以给我个星标⭐,第一时间收到推送







相关文章


















最新发布









推荐教程
-
 视频剪辑培训十大常见误区,资深剪辑师避坑指南
视频剪辑培训十大常见误区,资深剪辑师避坑指南 -
 最新就业趋势下建模培训必备的7项专业技能
最新就业趋势下建模培训必备的7项专业技能 -
 最新十大游戏开发培训机构实战课程对比评测
最新十大游戏开发培训机构实战课程对比评测 -
 优质动漫绘画培训机构筛选标准全攻略
优质动漫绘画培训机构筛选标准全攻略 -
 免费影视制作资源库:专业软件与插件合集推荐
免费影视制作资源库:专业软件与插件合集推荐 -
 零基础影视剪辑教程:30天掌握核心剪辑思维
零基础影视剪辑教程:30天掌握核心剪辑思维 -
 剪辑师培训全流程:从基础剪辑到高级特效指南
剪辑师培训全流程:从基础剪辑到高级特效指南 -
 短视频与长视频剪辑师培训需求差异深度解析
短视频与长视频剪辑师培训需求差异深度解析 -
 跨平台短视频培训:抖音B站小红书运营差异
跨平台短视频培训:抖音B站小红书运营差异 -
 视频剪辑避坑指南:识别优质课程的七个维度
视频剪辑避坑指南:识别优质课程的七个维度 -
 AI技术融合:3d建模培训班最新行业趋势解析
AI技术融合:3d建模培训班最新行业趋势解析 -
 Maya与Blender动漫制作软件对比全攻略
Maya与Blender动漫制作软件对比全攻略 -
 免费手绘学习资源库:线稿素材与笔刷合集推荐
免费手绘学习资源库:线稿素材与笔刷合集推荐 -
 插画培训价格解析:不同课程性价比深度对比
插画培训价格解析:不同课程性价比深度对比 -
 好莱坞认证课程:国际影视制作标准实战解析
好莱坞认证课程:国际影视制作标准实战解析 -
 如何选择游戏开发引擎?Unity与Unreal对比测评
如何选择游戏开发引擎?Unity与Unreal对比测评
猜你喜欢










优秀作品赏析

作 者:李思庭
所学课程:2101期学员李思庭作品

作 者:林雪茹
所学课程:2104期学员林雪茹作品

作 者:赵凌
所学课程:2107期学员赵凌作品

作 者:赵燃
所学课程:2107期学员赵燃作品
