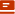 火星网校
火星网校
做废了1000条AI视频后我总结出6个画面一致性的方法
 作者:星火流萤
发布时间: 2026-07-04 11:08:33
浏览量:0次
作者:星火流萤
发布时间: 2026-07-04 11:08:33
浏览量:0次
做AI视频的人都知道一个痛:
单个镜头看着都不错,剪辑到一起就"跳戏":上一秒暖黄烛光,下一秒冷白日光灯;墙上的画框从巴洛克变极简,角色换个镜头就换了张脸。
有创作者分享过一组真实数据:
一条40秒的室内短片、12个镜头,前后生成了100多条素材,能用的不到20条。废掉的80多条里,一大半单帧都很惊艳——问题全出在镜头之间的不一致上。
这不是模型不够强,而是大多数人还没学会"控制场景"。本文整理了6种经过实战验证的方法,从零成本到专业级,帮你从盲目抽卡变成精准导演。
为什么AI视频总爱"跳戏"?
理解原因,才能对症下药。
AI视频生成器把每个镜头当作独立任务处理。它没有"上一个镜头长什么样"的记忆——每次生成都是从零开始的概率采样。即使你用完全相同的提示词,随机性也会让输出产生偏差。
这跟传统拍片完全不同。传统拍摄有真实演员、固定布景,天然保持一致。AI视频里不存在这种持久性——你得手动建立"一致性锚点"。
具体来说,一致性分两个层面:
场景一致性:同一个房间,换机位后墙壁、家具、光影不能变
角色一致性:同一个人,换镜头后脸型、发色、服装不能变
下面6种方法,分别解决这两个层面的问题。按难度从低到高排列,新手可以从方法1开始试。
方法1:提示词锚定法(零成本,立即可用)
适用人群:所有人,尤其是刚入门的新手
解决层面:角色一致性
需要工具:任何文生视频工具(可灵、即梦、Runway等均可)
最简单的方法,不需要任何额外工具。核心思路:在每个镜头的提示词里,写入完全相同的、具体的角色描述,形成文本"锚点"约束模型。
怎么做
第一步:写一段详细的角色描述
关键是"具体到可量化"。模糊的描述产生模糊的一致性。
❌ 弱锚点(太模糊):
一位年轻女性,黑色头发
✅ 强锚点(具体且可量化):
一位30岁的东亚女性,齐肩直黑发,棕色眼睛,浅色皮肤,穿合身的红色皮夹克搭配白色圆领T恤,深蓝色修身牛仔裤,白色运动鞋
第二步:复制到每个镜头
把这段描述完整复制到每一个包含该角色的提示词中。只改动作和机位,不改角色描述。
第三步:统一视觉风格
在所有提示词中保持相同的风格描述,比如"电影级,35mm胶片拍摄,蓝绿和橙色调色"。
多镜头示例
镜头1(全景):全景镜头,一位30岁的东亚女性,齐肩直黑发,穿红色皮夹克和白色T恤,在黄金时刻穿过繁忙的城市集市,电影级光效,缓慢跟踪拍摄
镜头2(中近景):中近景,一位30岁的东亚女性,齐肩直黑发,穿红色皮夹克和白色T恤,在集市摊位前挑选水果,温暖自然光,浅景深,固定机位
镜头3(过肩):过肩镜头,一位30岁的东亚女性,齐肩直黑发,穿红色皮夹克和白色T恤,在户外集市向摊贩付款,黄金时刻逆光,镜头缓慢推近
效果与局限
- 效果:对特征鲜明的角色(亮色服装、独特发色、标志性配饰)效果出人意料地好;完全免费;适用于所有文生视频工具
- 局限:精确度不如视觉参考方法;细微特征(特定脸型、精确比例)不够可靠;角色越复杂或机位变化越大,效果越差
方法2:参考图驱动法(图生视频 I2V)
适用人群:有一定图像生成基础的创作者
解决层面:角色一致性
需要工具:AI图像生成器(Midjourney、Flux等)+ 支持图生视频的平台
目前最可靠的角色一致性方法。不用文字描述角色长相,直接把角色图片喂给模型,让模型从这张图开始生成视频。模型使用参考图的像素数据作为扩散过程的起点,角色的面部、服装和身体比例都从第一帧就锚定。
怎么做
第一步:创建角色参考图
用Midjourney、Flux等工具生成角色图,或使用真实照片。准备3-5张不同角度的图(正面、四分之三侧面、侧面)。
参考图质量直接影响输出一致性,注意以下要点:
-
分辨率至少1024×1024像素 -
角色与背景有清晰分离 -
光线一致,避免极端阴影或高光 -
自然姿势,便于模型进行动画化 -
服装在所有参考图中保持一致
第二步:上传参考图到视频生成器
将图像上传到支持"图生视频"(I2V)的平台。
第三步:写运动提示词
关键:描述角色"怎么动",不要描述"长什么样"——模型已经能看到。
✅ 正确写法:
主体缓慢向右转头微笑,微风吹动头发,镜头缓慢推近面部
❌ 错误写法:
一个黑发女性穿着红夹克转头微笑(模型已有参考图,不需要重复描述外貌)
主流工具对比
效果与局限
- 效果:所有方法中角色一致性最高;无需训练,设置简单;适用于大多数主流AI视频生成器
- 局限:角色受限于参考图的起始姿势和构图;难以从单张参考图生成差异较大的机位;较长片段中角色可能偏离参考
方法3:场景九宫格法(锁定空间结构)
适用人群:做多镜头叙事、室内场景的创作者 解决层面:场景一致性 需要工具:AI图像生成器 + 视频生成器
这个方法来自创作者"仙人甲"的实战总结。核心思路:先用场景图生成房间的"九宫格"——9个不同角度的同一空间,把空间结构一次性锁死。AI看的是单张画面,它不知道空间结构。换个视角,椅子可能从左边跳到右边。九宫格强制AI在一个统一的空间框架里生成。
怎么做
第一步:生成场景九宫格
用现有场景图,让AI生成房间的九宫格视图(9个格子,每格代表一个摄影机位)。
第二步:筛选机位
从九宫格里挑出适合插入镜头的角度。
第三步:加入人物设定图
把选中的场景角度图与人物设定图合成,得到"初始场景图"。
第四步:送入视频模型
用初始场景图作为参考生成视频。因为所有镜头都来自同一个九宫格框架,物品位置不会乱换。
进阶版:把场景九宫格+人物设定图同时喂给模型的全能参考模式——场景图负责空间关系,人物图负责锁定角色,稳定性和效率兼顾。
提示词技巧:分段逐秒描述
不要写剧情简介式提示词。正确做法是分段逐秒描述:
0-3秒:中景,角色缓步走入画面左侧,暖色台灯光从右侧打来 3-6秒:近景,角色停下转头看向窗外,镜头缓慢推近 6-10秒:特写,角色面部表情从平静转为微笑,逆光轮廓
效果与局限
- 效果:一次九宫格搞定所有机位的空间一致性;特别适合室内大场景;无需反复试错
- 局限:需要先用图像模型生成九宫格,多了一步准备工作
方法4:720度全景图取景法(3D空间自由取景)
适用人群:需要多角度取景、追求沉浸感的创作者 解决层面:场景一致性 需要工具:支持720度全景生成的在线平台 + 视频生成器
前三种方法还在跟平面图较劲,这招直接给你一个3D房间。
怎么做
第一步:把场景图导入支持720度全景生成的在线平台,把平面图变成可以旋转的立体空间。
第二步:在3D空间中旋转到不同角度,截取多张场景图。
第三步:配合人物设定图使用,送入视频模型生成视频。
必须注意的坑:镜头畸变
720度是超广角,会在画面边缘产生严重畸变。解决方案:
-
在提示词里加上"50mm以上中焦镜头"限制 -
或用平台自带的摄影机控制功能锁定焦段
效果与局限
- 效果:真正实现3D空间内自由取景,场景一致性最强;不同角度截图都来自同一空间,天然保持统一
- 局限:支持全景生成的平台有限;畸变问题需要额外处理步骤
方法5:LoRA训练法(专业级角色锁定)
适用人群:需要角色反复出场、有长期项目的创作者
解决层面:角色一致性
需要工具:训练平台 + 图像生成器
LoRA(低秩适应)训练会创建一个小型模型适配器,把角色的视觉身份"固化"进去。训练完成后,无论什么角度、光照、场景,模型都能稳定生成你的特定角色。
可以理解为教模型一个新概念——你不再依赖模型对"一个人可能长什么样"的一般理解,而是给了它关于你角色的具体视觉词汇。
怎么做
第一步:收集训练数据
准备10-20张高质量角色图像(20-30张最佳),要求:
-
覆盖不同角度、表情、光照条件 -
背景干净 -
所有图像必须是同一角色 -
分辨率512×512或1024×1024
第二步:添加触发词
为每张图像添加描述文本和触发词(如"ohwx person")。
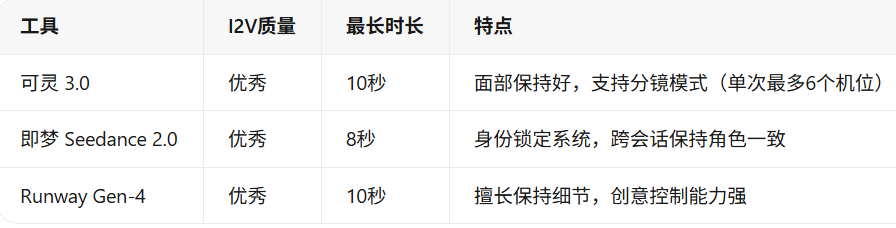
第三步:选择平台训练
第四步:使用
在提示词中引用触发词即可调用。适配器文件通常50-200MB,可无限复用,也可与其他LoRA组合。
效果与局限
- 效果:适用于各种姿势、场景和光照条件;一旦训练完成可无限复用;角色一致性灵活度最高
- 局限:需要收集训练数据集;训练耗时30分钟到数小时不等;有算力或平台费用;对新手技术门槛较高;而且seadance2.5推出后这个方法对新手已经不再适用了。
方法6:后期换脸修补法(兜底方案)
适用人群:所有创作者,作为其他方法的补充
解决层面:角色面部一致性
需要工具:换脸工具
把角色一致性当作"后期问题"而非"生成问题"。先用任何方法生成视频,专注获得最佳运动和构图,最后用换脸工具统一面部。将面部身份与视频生成过程完全解耦。
怎么做
第一步:用任何方法生成视频(文生视频、图生视频均可)
第二步:准备目标角色的清晰正面照,光线均匀
第三步:用换脸工具处理面部明显偏离的片段
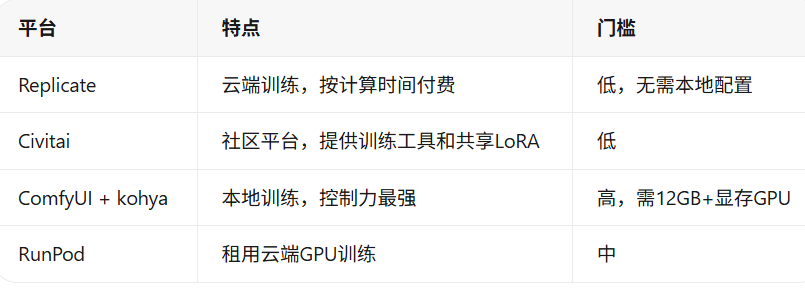
推荐工具
效果与局限
- 效果:适用于任何来源的视频;条件良好时能实现像素级面部一致性;有免费开源工具可用
- 局限:极端头部角度、强光照或快速运动时可能不自然;每个视频需额外处理时间;源素材分辨率低时效果下降
伦理提醒:换脸技术涉及深度伪造问题。用于自己的AI原创角色通常可以接受;使用真人面部必须获得明确授权。许多平台在服务条款中明确禁止深度伪造内容,使用时务必了解平台规则。
组合使用建议
这6种方法不是非此即彼的,最强的做法是组合使用:
新手组合:提示词锚定 + 参考图驱动 零成本起步,覆盖角色一致性基本需求。适合刚入门、不想折腾工具链的创作者。
进阶组合:场景九宫格 + 参考图驱动 + 分段逐秒提示词 场景和角色双重锁定,废片率大幅下降。适合做多镜头叙事短片。
专业组合:LoRA训练 + 场景九宫格 + 后期换脸 + 统一调色 全链路一致性控制,适合商业级产出。角色用LoRA锁定,空间用九宫格锁定,面部偏差用换脸兜底,最后统一调色收尾。
5个常见错误
1. 同时改太多变量
新场景+新角度+新光照+新动作=身份漂移。每次场景转换只改一个元素,其他保持不变。
2. 用低质量参考图
模糊、太小、光线差的参考给模型微弱信号。垃圾进,垃圾出。参考图至少1024×1024,光线充足,背景干净。
3. 提示词忽略服装
服装是重要的身份锚点。不指定,模型就自由发挥——自由发挥是一致性的大敌。
4. 没有锚定场景
先生成最好的角色镜头作为锚点,再以它为参考生成其他镜头。没有锚点,每个镜头各自漂移。
5. 忘了统一调色
即使角色一致,不同生成的色温和对比度会有差异。最后导入DaVinci Resolve、CapCut等剪辑软件统一调色,营造"一次拍完"的感觉。特别注意肤色统一,轻微的肤色偏移也会打破一致性观感。
写在最后
观众不一定能说出窗户位置不对,但他们的眼睛会感到不对。当你把所有空间关系都理顺了,观众说不出为什么,但会说"这个视频看起来真舒服"。
这种感觉背后有一个朴素的道理:
我们对真实世界的认知,本质上是对空间的记忆。你在一个房间里,换了个角度,壁炉还在那里,窗还在那里,你的大脑默默确认了这个空间是真实的。穿帮的本质,不是哪里画错了,而是你打碎了观众心里那张隐形的平面图。
模型的进步在扩大你能做到的上限,但你做出来的东西的下限,永远取决于你对影像有多深的理解。搞懂空间逻辑,AI才真正听你使唤。
参考来源
还想看什么?可以在评论区留下你的?,我会继续为大家整理AI前沿资讯~
你也可以点击文末左下角“阅读原文”咨询课程,所有这些内容,咱们火星的长期就业班都会教!
相关阅读



如果觉得有用,随手点个赞、在看、转发。也可以给我个星标⭐,第一时间收到推送







相关文章












最新发布







推荐教程
-
 视频剪辑培训十大常见误区,资深剪辑师避坑指南
视频剪辑培训十大常见误区,资深剪辑师避坑指南 -
 最新就业趋势下建模培训必备的7项专业技能
最新就业趋势下建模培训必备的7项专业技能 -
 最新十大游戏开发培训机构实战课程对比评测
最新十大游戏开发培训机构实战课程对比评测 -
 优质动漫绘画培训机构筛选标准全攻略
优质动漫绘画培训机构筛选标准全攻略 -
 免费影视制作资源库:专业软件与插件合集推荐
免费影视制作资源库:专业软件与插件合集推荐 -
 零基础影视剪辑教程:30天掌握核心剪辑思维
零基础影视剪辑教程:30天掌握核心剪辑思维 -
 剪辑师培训全流程:从基础剪辑到高级特效指南
剪辑师培训全流程:从基础剪辑到高级特效指南 -
 短视频与长视频剪辑师培训需求差异深度解析
短视频与长视频剪辑师培训需求差异深度解析 -
 跨平台短视频培训:抖音B站小红书运营差异
跨平台短视频培训:抖音B站小红书运营差异 -
 视频剪辑避坑指南:识别优质课程的七个维度
视频剪辑避坑指南:识别优质课程的七个维度 -
 AI技术融合:3d建模培训班最新行业趋势解析
AI技术融合:3d建模培训班最新行业趋势解析 -
 Maya与Blender动漫制作软件对比全攻略
Maya与Blender动漫制作软件对比全攻略 -
 免费手绘学习资源库:线稿素材与笔刷合集推荐
免费手绘学习资源库:线稿素材与笔刷合集推荐 -
 插画培训价格解析:不同课程性价比深度对比
插画培训价格解析:不同课程性价比深度对比 -
 好莱坞认证课程:国际影视制作标准实战解析
好莱坞认证课程:国际影视制作标准实战解析 -
 如何选择游戏开发引擎?Unity与Unreal对比测评
如何选择游戏开发引擎?Unity与Unreal对比测评
猜你喜欢










优秀作品赏析

作 者:李思庭
所学课程:2101期学员李思庭作品

作 者:林雪茹
所学课程:2104期学员林雪茹作品

作 者:赵凌
所学课程:2107期学员赵凌作品

作 者:赵燃
所学课程:2107期学员赵燃作品
